

Decentralized Objects with Martin Kleppmann

Podcast: Play in new window | Download
Subscribe: RSS
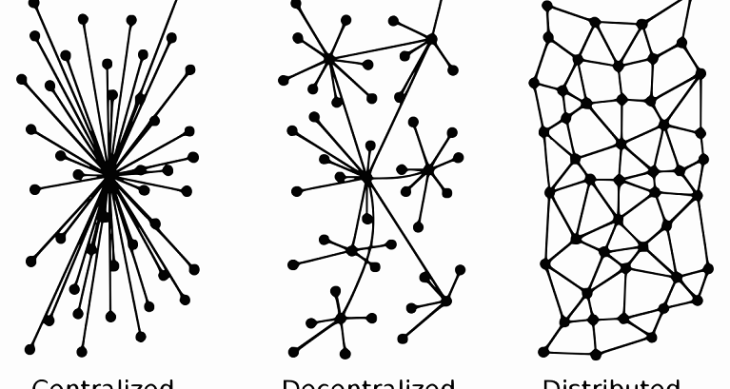
 The Internet was designed as a decentralized system.
The Internet was designed as a decentralized system.
Theoretically, if Alice wants to send an email to Bob, she can set up an email client on her computer and send that email to Bob’s email server on his computer. In reality, very few people run their own email servers. We all send our emails to centralized services like Gmail, and connect to those centralized services using our own client—a browser on our laptop or a mobile application on our smart phone.
Gmail is popular because nobody wants to run their own email server—it’s too much work. With Gmail, our emails our centralized, but centralization comes with convenience.
Similar centralization happened with online payments.
If Alice wants to send $5 to Bob, she needs to go through centralized banking infrastructure. Alice tells her bank to send $5 from her bank account to Bob’s bank account. This is not how it works in the physical world. if Alice wants to pay cash to Bob, she doesn’t have to go and meet him at a physical bank. She just takes out a $5 bill from her wallet and hands it to him.
The invention of Bitcoin proved that digital wallets and peer-to-peer payments are possible. But running your own wallet is like running your own email server. It is inconvenient, and so we trade decentralization for convenience once again. We use services like Coinbase, where users buy and sell cryptocurrencies in a centralized provider.
There are people in the cryptocurrency community who hate the idea of Coinbase. These people keep their cryptocurrency spread out on their own hardware wallets. Some of these people also run their own email servers.
Are these people just adding unnecessary inconvenience to their lives for no reason? No. These are smart, successful people. They don’t like to waste time. So what are they doing running their own email servers?
Distributed systems theory teaches the risk of centralized computer systems. If you have a single server that all your communication has to be routed through, your computer network will stop functioning if that server dies.
Today, civilization is reliant on centralized computer systems. This is fundamentally dangerous. The 2008 financial crisis proved how risky it is to centralize our money in the hands of a few people. The Equifax breach proved how risky it is to centralize our identity in the hands of a few people.
What happens if Dropbox runs out of money and has to shut down? What happens if all of the data centers at Amazon Web Services get wiped simultaneously? What happens if Coinbase gets hacked and every user at Coinbase loses all their money?
We have seen centralized systems collapse. The people who are running their own email servers are not crazy. Even if Gmail disappears tomorrow, they will still have access to their emails. With the example of email, we see that deploying and managing a decentralized system is possible.
Decentralization is a desirable feature of computer systems. So how do we make more of our applications decentralized?
The cypherpunks were working for decades to make decentralized money a reality. Satoshi Nakamoto invented the blockchain, and we now have a computer science construct that enables decentralized money. The blockchain also enables many other decentralized applications.
By solving a specific problem, Satoshi came up with a general solution. This is how progress often happens in computer science. In order to fix a system, we create a new tool. That tool can be applied to other systems that we don’t anticipate.
The blockchain is a tool that solves one set of problems in distributed systems. Conflict-free replicated data types are another type of tool.
Conflict-free replicated data types (or CRDTs for short) are objects that can be mutated by multiple users at the same time without creating data corruption. The most common example of a conflict-free replicated data type is the shopping cart.
Let’s say Alice and Bob share an account on an ecommerce web site. Alice is building a house, and she wants to buy some tools online. Alice has a shopping cart with a hammer in it. Bob logs into the ecommerce web site from a different computer at the same time Alice is logged in. Bob just wants to buy a tuxedo—he doesn’t know why Alice left a hammer in the shopping cart, so he clicks a button to remove all the items from the shopping cart. At the exact same moment, Alice clicks from her computer to add a drill to the shopping cart.
The server receives both requests: Bob wants to delete all items in the shopping cart, Alice wants to add a drill to the shopping cart. Both requests occurred at the exact same time, but we have to decide how to process them in some order. This is a situation known as a conflict.
Which request should execute first? Should the resulting shopping cart be empty? Should the shopping cart only have a drill in it? In either case, Alice or Bob is going to be disappointed—there is no way to avoid that. But we need some way to resolve the conflict deterministically. We do not want to have to send a message to both Alice and Bob that says “sorry, our shopping cart cannot handle your request. Please try again later.”
We need the shopping cart to be a conflict-free shopping cart—and today’s episode is about the different techniques that can be used for conflict resolution.
The shopping cart is a simple example where user collaboration leads to conflicts. Imagine all the other ways you collaborate with other users: chat systems like Slack, social networks like Facebook, document systems like Google Docs.
One way to resolve a conflict is through a technique called operational transform. Operational transform requires all the operations in the distributed system to be funneled through a centralized server. When a conflict occurs, the centralized server detects the problem and figures out how to resolve it.
Google Docs uses operational transform to resolve the frequent conflicts that occur when two users are sharing a text document. But operational transform only works if you have a centralized server.
An alternative solution is conflict-free replicated data types, which maintain each user’s replica of the data in a format that allows the client copies to resolve conflicts in a peer-to-peer fashion—without a centralized server.
Last example: Alice and Bob are now collaborating on a document that uses a CRDT data structure under the hood. Whenever they send their local changes to each other, any conflicts that occur can be resolved directly on the client. Alice and Bob can collaborate on a document just like they can send emails to each other.
With CRDTs, we can build decentralized, collaborative applications. But CRDTs are hard to use. Just like with blockchain technology, we don’t yet have the simple, elegant abstractions that let inexperienced programmers build peer-to-peer applications without the fear of conflicts.
Martin Kleppman is a distributed systems researcher and the author of Data Intensive Applications. Martin is concerned by the centralization of our computer networks, and he works on CRDT technology in order to make it easier for people to build peer-to-peer applications.
Most of the people who know how to build systems with CRDTs are distributed systems PhDs, database experts, and people working at huge internet companies. How do you make developer-friendly CRDTs? How do you allow random hackers to build peer-to-peer applications that avoid conflicts? Start by making a CRDT out of the most widely used, generalizable data structure in modern application development: the JSON object.
In today’s episode, Martin and I talk about conflict resolution, CRDTs, and decentralized applications. This is Martin’s second time on the show, and his first interview is the most popular episode to date. You can find a link to that episode in the show notes for this episode, or you can find it in the Software Engineering Daily app for iOS and for Android. In other podcast players, you can only access the most recent 100 episodes. With these apps, we are building a new way to consume content about software engineering. They are open-sourced at github.com/softwareengineeringdaily. If you are looking for an open source project to get involved with, we would love to get your help.
Transcript
Transcript provided by We Edit Podcasts. Software Engineering Daily listeners can go to weeditpodcasts.com/sed to get 20% off the first two months of audio editing and transcription services. Thanks to We Edit Podcasts for partnering with SE Daily. Please click here to view this show’s transcript.






