

10 Privacy-enhancing Technologies Every Engineer Should Know About


As engineers, we need to secure and protect sensitive data to prevent its misuse and comply with various data protection laws, while still supporting data-driven workflows like machine learning, analytics, or data sharing. Luckily there’s amazing innovation going on in the privacy and security space that can help us not only maintain our customers’ data privacy but provide high data utility at the same time.
In this article, I discuss 10 different privacy-enhancing technologies (PETs) that all engineers should be aware of as these PETs start to become practical and commercially available.
What are Privacy-enhancing Technologies?
Privacy-enhancing technologies include any technology that increases the privacy and security of sensitive data – critical information like customer names, phone numbers, email addresses and social security numbers (SSNs). Whether you’re looking to ensure compliance with GPDR or CCPA, or harden your systems against the next data breach, these technologies are an indispensable part of a full-stack developer’s toolkit.
Although they take many forms, privacy-enhancing technologies tend to emphasize a few common themes:
- De-identification
- Obfuscation (tokenization, encryption, pseudoanonymization)
- Isolation or centralization of sensitive data
- Zero trust / distributed trust (including multi-party computing)
But before looking at a range of privacy-enhancing technologies, it’s worthwhile to consider why these technologies are so valuable to software engineers.
Why are Privacy-enhancing Technologies Important?
Privacy-enhancing technologies are important because individuals have a right to the privacy of their sensitive personal data. They expect the apps and websites that they use to protect this data and only use it for intended purposes (instead of acquiring a phone number for 2FA and then using it for advertising).
The rising awareness of this right has been spurred by the ever-increasing number of data breaches in recent years, and regulators have responded by creating new data privacy regulations like CCPA (California), CPA (Colorado), GDPR (EU), and DCIA (Canada) – to name just a few.
When you consider the complexity of protecting sensitive information while retaining data utility, and the headaches and costs of a significant data breach – now an average of $4 million, and climbing – the importance of privacy-enhancing technologies becomes obvious.
Examples of Privacy-enhancing Technologies
Any developer who works with sensitive data should be familiar with the full range of privacy-enhancing technologies they can use to protect this data. My goal in writing this is to give you at least a passing familiarity with the full range of these technologies, so that you’ll know which tools to investigate more deeply when you face a new data privacy issue.
Secure Multiparty Compute
Secure multiparty compute (MPC) is a branch of cryptography that distributes computation across multiple parties where no individual party can see the other party’s data. The core idea is to give different parties a way to compute data and arrive at a mutually desired result without divulging their private data to other parties.
A classic example use case for this protocol is the average salary problem: How can a group of workers compute their average salary without divulging their own personal salary to others?
MPC can solve this problem using the following series of operations:
- Number the workers from first to last in an arbitrary order
- The first worker chooses a very large random number, adds their salary to that number, and then forwards the result to the second worker (see image below)
- The second worker adds their salary to the shared value and then forwards that result to the third worker and so on until all workers have contributed their salary
- The last worker adds their salary and sends the final result to the first worker
- Since the first worker chose the random number, they now subtract that number from the total number, giving them the sum of all salaries. They can then compute the average by dividing this result by the total number of workers.
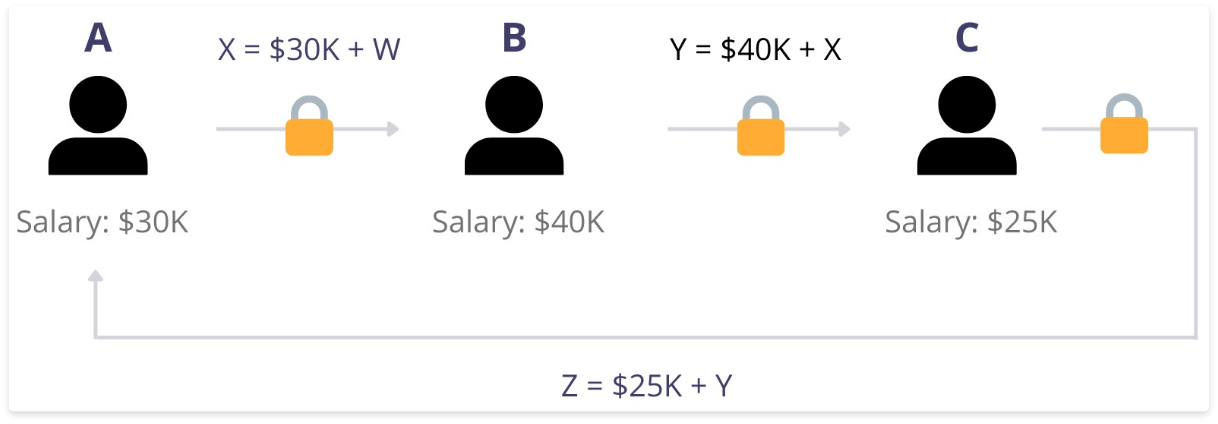
Example of MPC: Worker A chooses a random number W and adds that to their salary before passing the sum to Worker B, who adds their salary to this sum and then passes that to Worker C, and so on. Worker A gets the final sum and can calculate the average salary.
MPC was introduced in the early 1970s and then first formalized in the late 1980s, but it’s only recently moved beyond something studied in academia to solving real-world problems for commercial products. MPC is now being used for a wide range of applications, including: fraud detection, heart disease analysis, and feature aggregation across private datasets.
It’s an extremely powerful approach to privacy, but there are some limitations. Using MPC adds both computational overhead to an existing system as well as a high communication cost between different parties. This makes using MPC impractical for many problems.
De-identification Techniques
De-identification is the process of removing personal information from a data set. There are multiple de-identification methods, such as tokenization and k-anonymization.
Tokenization
Tokenization is a non-algorithmic approach to data obfuscation that swaps sensitive data for tokens. For example, a customer’s name like “John Smith” could be replaced by a tokenized string like “7afd3186-369f-4898-ac93-3a4e732ebf7c”. Since there’s no mathematical relationship between “John Smith” and the string “7afd3186-369f-4898-ac93-3a4e732ebf7c”, there’s no way to get the original data from the tokenized data without access to the tokenization process.

A simple tokenization system for names and email addresses
There are a variety of techniques and styles of tokenization, including length-preserving tokenization, format-preserving tokenization, and random versus consistent tokenization. Different approaches have different tradeoffs and can help support different use cases.
You can safely store tokens in your database or downstream services because they have no exploitable value. And many analytics and machine learning workflows can run directly against the tokenized data.
K-anonymization
K-anonymization was first proposed in the late 90s by researchers Latanya Sweeney and Pierangela Samarati. K-anonymity is a property of data. A data set is said to have the k-anonymity property if the information for each person in the data set can’t be distinguished from at least k-1 individuals.
This is a “safety in numbers” approach. Essentially, if everyone belongs to a group, then any of the records within the group could correspond to a single individual. The downside of k-anonymization is that there is no randomization, so an attacker can still make inferences about the data. Additionally, if an attacker knows some information about an individual, they can use the groups to learn additional information about that person. For example, if all women in our data set over the age of 60 have breast cancer and the attackers know that Julie is over 60 and in the data set, then now the attackers know Julie has breast cancer.
Like many PETs in this list, k-anonymization is a powerful tool if it’s combined with additional technologies and reinforced by putting the right safeguards in place.
Pseudoanonymization
Pseudoanyonymization is a form of obfuscation that hides the identity of an individual by replacing field values with pseudonyms. With pseudoanyonymization, only a portion of the identifying data is removed – enough that the data values can’t be linked to the person or thing they refer to (the “data subject”)
There are a variety of pseudoanyonymization methods including scrambling, whereby the original values are mixed with obfuscated letters, and data masking, where some part of the original data is hidden.
With pseudoanyonymization, there’s always a risk of re-identification. Different methods carry different risks, and some methods aren’t compliant with certain regulations. And while pseudoanyonymization has many uses, this method alone isn’t a complete data privacy solution.
Homomorphic Encryption
Basic forms of encryption have been around since 1900 BC and modern techniques like RSA, AES, and DES are widely used for secure data transmission and storage. However, the downside of all of these techniques is that in order to perform operations on the data, you need to decrypt it first. This opens up a potential attack surface as decrypted data is cached in memory, or because small coding errors can result in sensitive unencrypted data showing up in your log files or other places. This increases the scope of your security and compliance problems.
Homomorphic encryption is widely considered the “gold standard” of encryption. It’s a form of encryption that permits you to perform computations on encrypted data without first decrypting it. On the surface, this sounds amazing. Full data utility while maximizing security.
However, in practicality fully homomorphic encryption suffers from performance challenges. It’s just too slow to offer reasonable performance, and it requires too much computing power for companies to use.
Homomorphic suffers from performance challenges because it’s very complex and needs to support nearly any operation on encrypted data. This is an ideal capability in theory, but the reality for most software engineers is that they don’t need to perform any arbitrary operation on data. They typically need to perform a few very specific operations.
This is especially true when we are talking about sensitive customer data. It doesn’t make sense to multiply or divide two phone numbers, or even take an arbitrary substring. Phone numbers, dates of birth, social security numbers, and many other forms of sensitive customer data have very specific formats and components. And the type of operations you want to perform are already predetermined – so why suffer slow performance to support unneeded operations on encrypted data?.
Enter polymorphic encryption. Like homomorphic encryption, polymorphic encryption supports operations on encrypted data, but is specifically designed for supporting the types of use cases and operations engineers typically need to perform on sensitive data. For example, indexing and decrypting only the last four digits of a social security number or determining if a customer’s credit score is above or below a given threshold without actually seeing the customer’s credit score.
Polymorphic encryption is an incredibly powerful PET that is enterprise-ready today.
Federated Learning
Federated learning is a decentralized form of machine learning. In machine learning, typically training data is aggregated from multiple sources (mobile phones, laptops, IoT devices, etc.) and brought to a central server for training. However, from a privacy standpoint, this obviously has issues.
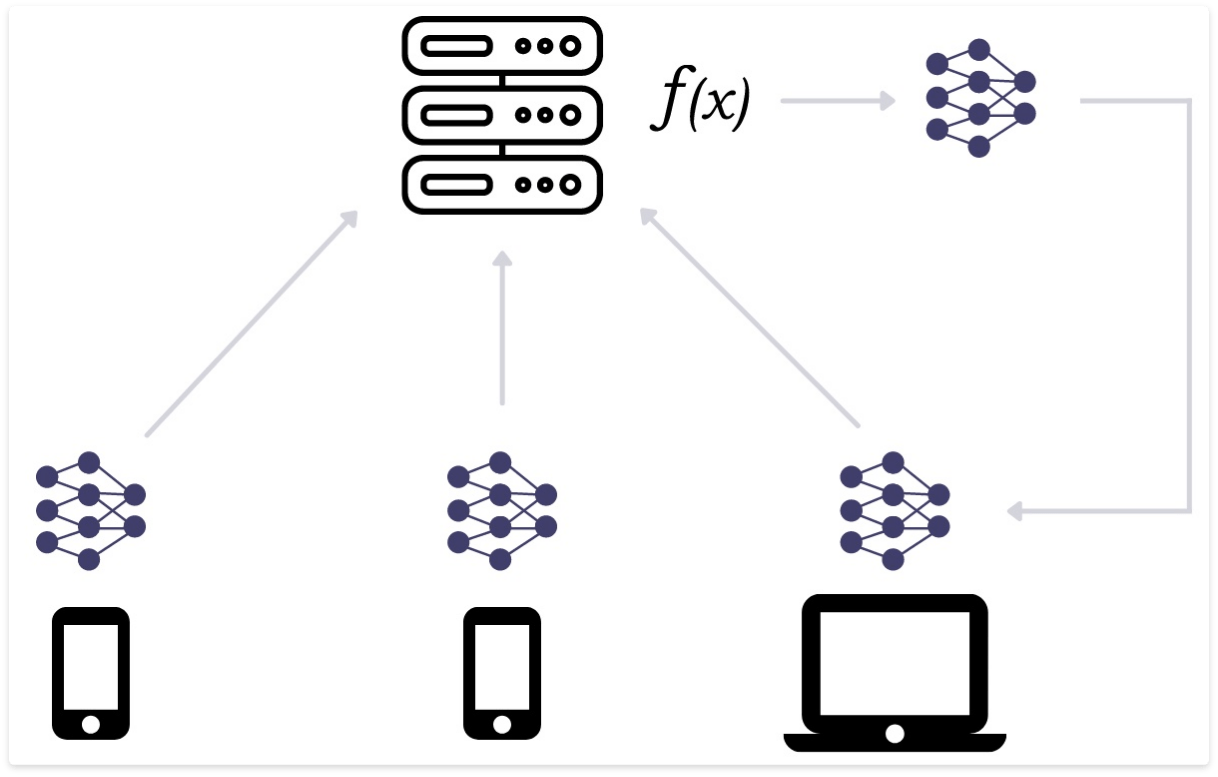
Example of federated learning. Training happens locally and results are reported centrally.
In a federated learning model, training happens locally and the results are reported to the centralized server, rather than the raw inputs. For example, the centralized machine learning application is available directly on all devices. The local model learns and trains itself on the device based on the user’s input and device usage. The device then transfers only the training results from the local copy back to the central server.
The results from all decentralized devices are aggregated together, but without seeing any of the user data. Users’ devices can then be updated with the newly-trained central model as shown in the image above.
You can try this out yourself with Google’s Federated Learning for Image Classification codelab.Federated learning has a few limitations, though. It requires frequent communication between devices and the central server, so it requires a lot of network bandwidth. Additionally, local training requires enough local computing power and memory to actually train the model. However, companies like Google and Amazon are heavily invested in this PET and there have been multiple breakthroughs to help reduce the cost of computation and improve communication efficiency.
Zero-Knowledge Proof
Imagine if you could go to a bar and order a drink and instead of the bartender asking to see your driver’s license to check your birthdate and then do the math to figure out if you’re old enough, they could simply ask, “Are you old enough to purchase alcohol?”, and you could respond “Yes” and they could know for sure whether your “Yes” was true or not? This type of scenario is possible with zero-knowledge proofs.
Zero-knowledge proof is a method that lets one party prove to another party that a given statement is true without revealing any information beyond the fact that the statement is true.
A classic example of a zero-knowledge proof is the cave of Ali Baba.
In this scenario there are two characters, Peggy (the prover) and Victor (the verifier). Both Peggy and Victor find themselves at the entrance to the cave, which has two distinct entrances to two different paths (A and B). Inside the cave there’s a door that connects both paths, but can only be opened with a secret code. Peggy owns the code and Victor wants to have it, but first Victor wants to make sure Peggy isn’t lying about owning the code.
How can Peggy show Victor that she owns the code without revealing it?
To do this, Peggy can enter the cave by either door (A or B). Once inside, Victor approaches the cave and shouts to Peggy to return by one of the two paths, chosen arbitrarily. If Victor yells to return via the A path but Peggy is currently in the B path, she can only return via A if she indeed has the secret code. Of course, Peggy might get lucky if she’s lying and already be in the A path, but as long as this process is repeated enough times, Peggy can only always return along the correct path if she has the secret code.
In terms of practical applications, a zero-knowledge cryptographic method is being used by the cryptocurrency Zcash. It’s also being used by customers of ING to prove that their income is within an admissible range without revealing their exact salary.
The challenges with zero-knowledge proofs that the answer isn’t 100% guaranteed, and that it’s computationally intensive. Many interactions are required between the prover and verifier to reduce the probability of misrepresentation to an acceptable level. This makes this impractical for slow or low-powered devices.
Differential Privacy
Differential privacy is a PET that’s seeing growing commercial interest. The idea of differential privacy is that by introducing a small amount of noise into a data set, a query result can’t be used to infer much about a single individual. Differential privacy isn’t a specific process like de-identification, but a property that an algorithm or process can have.
With differential privacy, you’re adding a layer of privacy by adding noise to the original data. As a consequence, any modeling or analytics performed using the resulting data has diminished accuracy.
The key to using differential privacy well is to carefully balance the need for accurate results with the need to protect an individual’s privacy by obfuscating those results.
Synthetic Data
Synthetic data (or “fake data”) is artificially generated data that mirrors the patterns and composition of the original dataset. It’s a type of data anonymization. Synthetic data is a great solution for certain use cases, like giving engineers something that has similar properties to production data for testing purposes without exposing actual customer PII. Synthetic data is also widely used for training the machine learning models used in fraud detection systems.
It’s a complex process to synthetically generate data that looks and feels real enough to be useful for testing or other applications. For example, if a business has multiple databases with independent tables containing a customer name, the same customer in both databases would have the same name. Ideally the synthetic data that’s generated for this business is able to capture this pattern.
That’s a complex problem, but there are a number of companies with commercially available solutions today.
Trusted Execution Environment
A Trusted Execution Environment (TEE) is a hardware-based approach to privacy. With TEE, a CPU has a hardware partition from the main computer’s process and memory. Data within the TEE can’t be accessed from the main processor and the communication between the TEE and the rest of the CPU is encrypted. Operations on the encrypted data can only take place within the TEE.
Intel, AMD, and other chip manufacturers are now offering TEE chips. AWS Nitro Enclaves uses this technology to create isolated compute environments suitable for processing highly sensitive data like PII while keeping it secure and private.
Data Privacy Vault
A data privacy vault isolates, secures, and tightly controls access to manage, monitor, and use sensitive data. It’s both a technology and architectural design pattern. A data privacy vault combines multiple PETs, like encryption, tokenization, and data masking along with data security techniques like zero trust, logging, and auditing, and the principle of isolation.

Example of using a data privacy vault. Sensitive data is sent to the vault at collection. Tokenized data is stored downstream.
A business that uses a data privacy vault moves their customer PII out of their existing data storage and infrastructure and into the vault, as shown in the image above. The data privacy vault becomes the single source of truth for all customer PII, effectively de-scoping the existing application infrastructure from the responsibilities of data security and compliance. This architectural design approach to data privacy carries another benefit: it significantly reduces the complexity of data residency or localization.
This technology was originally pioneered by companies like Apple and Netflix. Despite being widely regarded as a best-in-class approach to data privacy, the data privacy vault hasn’t seen widespread adoption outside of a few major technology companies. This is due to the complexity involved with building the vault system. It took Shopify three years and contributions from 94 engineers to build their version of a data privacy vault.
The Future of Privacy
Data privacy isn’t just about compliance, it’s also the right thing to do for your users. There’s a tremendous amount of growth and momentum in this space that’s going to help engineers build better, more secure systems while still allowing businesses to use the data they collect about customers to improve their products.
As these technologies become commercially available and abstraction layers like APIs and SDKs are developed, utilizing these technologies in our everyday engineering tasks will become as easy and commonplace as programmatically placing a phone call or issuing a credit card transaction.
Data privacy isn’t the CISOs job or the privacy officers’ job, it’s everyone’s job. As engineers who are often tasked with the technical aspects of securing sensitive data, it’s critical that we understand the landscape of privacy-enhancing tools and technologies. And, it’s vitally important that we use this understanding to follow privacy best practices and honor the trust placed in us when our users share their sensitive personal data.






