

Components of Modern Data Pipelines


Figure 1
Data flows to and from systems through data pipelines. The motivations for data pipelines include the decoupling of systems, avoidance of performance hits where the data is being captured, and the ability to combine data from different systems. Pipelines are also well-suited to help organizations train, deploy, and analyze machine learning models. Figure 1 provides a high-level overview of how a machine learning pipeline may be architected.
This article does not take a deep dive into the machine learning side of data pipelines. If you’re interested in learning about data engineering’s intersection with machine learning, check out this episode of Software Engineering Daily. This episode features two Stripe engineers, Rob Story and Kelly Rivoire, working on machine learning infrastructure, as well as an API they built for machine learning workloads.
Without systematized pipelines, a number of issues may arise. For example, systems with many data sources may suffer from increased complexity, especially as the number of data sources increase and the types of data change. Another example is data veracity; pipelines can ease the process of extracting, transforming, and loading (ETL) data.
Data pipelines can integrate with a number of systems, including visualization tools and third party software, such as Salesforce. Moving data into these kinds of systems is commonly one of the last steps in a data pipeline. More common is the movement of data into a data warehouse, lake, or mart. All of these data stores serve different purposes, each of which is explored later in this article.
Data processing systems sit on top of these data stores and transportation systems. The two main categories of data processing systems are online transaction processes (OLTP) and online analytical processing (OLAP). Each serves an important role within a system. As CEO of Starburst Justin Borgman notes in this episode of Software Engineering Daily, “You’re always going to need your OLTP operational style system to serve your application.” Starburst offers their own version of Presto, a popular, open-sourced OLTP system that originated at Facebook.

Figure 2
Many of the topics covered in this article are better explained with examples. The notion of a data pipeline encompasses an end-to-end system. As such, it is useful to examine a consistent hypothetical, while examining different components of the larger system. From this point forward, we’ll refer to a hypothetical startup called, “Claire’s Cakes,” an on-demand cake delivery service.
OLTP & OLAP
Online transaction processing (OLTP) and online analytical processing (OLAP) are the primary ways of characterizing systems. Don’t be fooled by the similarity of these acronyms: OLTP and OLAP systems are very different from one another.
Think of OLTP systems as managing organization’s day-to-day transactions; the system’s CRUD operations and database are optimized for transactional superiority. Some common examples of OLTP databases are MySQL, PostgreSQL, and MemSQL. If you’re interested in learning more about the technology backing common OLTP systems, check out these episodes of Software Engineering Daily.
OLAP systems lie on the other side of the coin. Rather than capturing and persisting data, OLAP systems help an organization generate insights about data. The arena of OLAP encompasses various types of OLAP such as relational (ROLAP), multidimensional (MOLAP), and hybrid (HOLAP). Check out these episodes of Software Engineering Daily to learn more about OLAP technology.

Figure 3
Let’s examine OLTP more closely. Typically, discussions about OLTP surround databases. OLTP databases process transactions. In the context of a data pipeline, these transactions are the events that affect an organization’s business applications. Building off of this point, it’s often useful for business applications to access records by row. So, OLTP systems often make use of SQL databases.
To understand why row-based access is more useful for business applications, let’s refer to a hypothetical series of events caused by one of the customers of Claire’s Cakes. The customer places an order for two cakes, adds a third cake to his order after placing the initial order, updates the drop-off location, and rates the cake courrier’s service after receiving his order. Accessing the database fields in a columnar fashion would be inefficient; all of the fields associated with this customer will be stored in a single row. So, row-based access is preferable in OLTP databases.
In addition to row-based access, OLTP databases have a number of other requirements. Former Uber software engineer Zhenxiao Luo states “reliability is more important” for OLTP systems than OLAP systems because OLTP systems “serve online data, so performance has a really real-time requirement.” Luo’s full interview on Software Engineering Daily provides an end-to-end overview of Uber’s data platform, including discussions of both OLTP and OLAP systems at Uber.
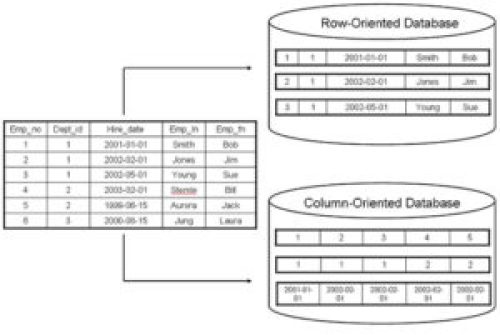
Figure 4
Let’s look at the other side of the coin: OLAP systems. At a high level, OLAP systems
are responsible for the parts of a data pipeline following initial storage in an OLTP database. Figure 3 illustrates the overarching theme in an OLAP system: data is taken from disparate data sources and loaded into a new kind of data store. This process is known as extract, transform, load (ETL), or extract, load, transform (ELT), in some cases. Data is typically moved to a data warehouse, lake, or mart. From here, data is queried to derive analytics.
OLAP systems can be divided into two large categories: relational online analytical processing (ROLAP) and multidimensional analytical processing (MOLAP). Each of these subcategories could be articles in and of themselves; we will not dive deeply into these. Essentially, ROLAP is OLAP applied to relational databases and MOLAP is OLAP applied to multidimensional databases. If you’re interested in learning more about the differences between these flavors of OLAP systems, check out this article.
The differences between OLAP and OLTP systems are most prominent when the MOLAP flavor of OLAP systems is considered. The most prominent characteristics of MOLAP are the storage of massive amounts of data, ability to optimize ad hoc queries, prioritization of response time over transaction throughput, and a column oriented storage model. Clearly, these stand in contrast to the canonical OLTP system.
Let’s examine why a column oriented storage model is beneficial for OLAP systems. Suppose a data scientist employed by Claire’s Cakes wants to calculate the daily total number of cakes ordered over the past week. He or she would want an efficient way of grabbing a particular field across all orders placed: number of cakes ordered. Querying a single field across unrelated entities highlights the benefit of columnar storage model: aggregation is more efficient. As George Fraser stated in this episode of Software Engineering Daily, “[…]column stores actually go way beyond just the file format. Every level of the database is implemented in different, and in many cases opposite, ways.”
Data Movement and Where Data Lives

Figure 5
The authoritative way to move data from one data store to another is by making use of an ETL process. ETL is an acronym for, “extract, transform, load.” George Fraser, the CEO of Fivetran, which is a company that builds data connectors, explains that ETL “just refers to the nitty-gritty of the process of getting data from a source […] into a database.”
An ETL process loads data into a kind of data store known as a data warehouse. Data warehouses have structured data; there is an exact schema for data loaded into a data warehouse. Not only does a schema improve how efficiently queries are served, but it also provides a level of consistency that’s able to serve the needs of employees across an organization.
Another common data movement pattern is ELT: extract, load, transform. Rather than applying structure before loading it, data is simply dumped into a data store. This kind of data store is known as a data lake. As one may imagine, loading data into a data lake is easier than that into a data warehouse: the data doesn’t need to be transformed before the loading step. However, this comes at a price: a schema is applied to data at query time.
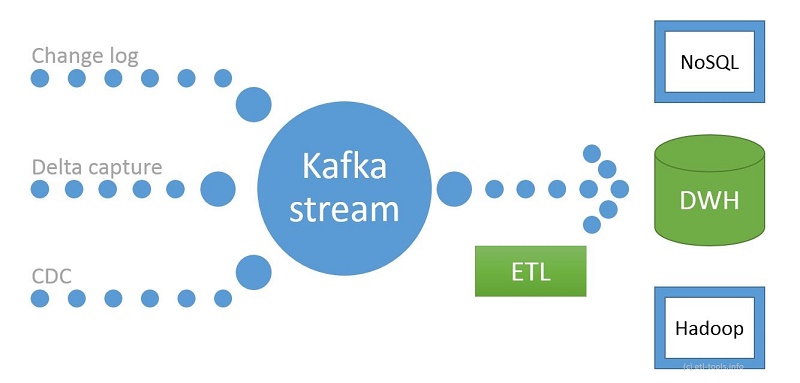
Figure 6
Regardless of ETL or ELT, there are two main processing paradigms in the world of data movement: batch and stream processing. A breakdown of batch and stream processing systems could be a separate article entirely. Batch processing performs ETL on chunks of data that have already been stored, whereas stream processing performs ETL on data that has yet to be persisted. Popular stream processing frameworks include Kafka, Flink, Samza, and Storm.
Batch processing can yield near real time analytics. However, near real time does not fit all business use cases. Stream processing is often used when real time analytics are required. If you’re interested in learning more about the differences between batch and stream processing, check out these related articles and podcasts.







