

Why Everyone Needs a Data Privacy Vault


For over 20 years, our unquenchable appetite for data has led to us inventing and investing in a myriad of technologies, like SQL and NoSQL databases, streaming services, data lakes and warehouses, machine learning, and many more. The demand for data isn’t slowing down, with 97.2% of organizations investing in big data and AI.
However, not all data is created equal.
We manage tons of data, but only a small amount of it is sensitive because it can be used to identify an individual. As an industry, we must shift our mindset to recognize that this data is special and must be isolated and protected differently than non-sensitive application data.
In this article, we take a deep dive into the challenges of managing sensitive user data, and discuss how leading technology companies are solving this problem using a zero-trust data privacy vault architecture. We’ll also discuss what goes into creating a zero-trust data privacy vault, and where it fits into your existing stack.
Data Privacy is a Difficult Engineering Problem
There’s a spectrum of solutions when it comes to the storage and handling of sensitive user data. Generally the more secure and sophisticated the approach, the more complicated the implementation.
For example, a sophisticated approach shown on the left side of the in the diagram below would use multiple privacy-preserving techniques like tokenization, access control, de-identification, and key management; but using these technologies would complicate our infrastructure and codebase. At the other end of this spectrum, shown on the right side of the diagram, we could just store everything in plain text, which is super simple to implement, but not very secure.

More Data Privacy Typically Means More Complexity
Most companies end up somewhere in the middle of these two extremes. Additionally, different teams within the same company might actually use different strategies, leading to a fragmented approach to data privacy that introduces its own headaches.
There’s also a tradeoff between maximizing privacy and security and the utility we can derive from sensitive data. For example, you could maximize data privacy by never storing any sensitive user data, but this would significantly hamper your company’s ability to take action on this data. And sometimes these actions are critically important, like contacting a customer who needs assistance or who is at risk of canceling their service. There are ways to overcome this tradeoff and maximize data privacy without sacrificing data usability, but doing this is far from easy.
The Intractability of Addressing Data Privacy with Point Solutions
Focusing on data privacy often comes after a growth phase for a business, when much of the initial infrastructure is already in place. Yet, at that point, everything’s been moving so fast that the company has lost track of where, why, and how all of the sensitive data is stored.
A survey by CIO.com in 2020 revealed that 20% of respondents feed their analytics and BI tools with 1,000 or more sources. Data gets copied, replicated, and becomes part of the existing applications, dashboards, and data pipelines – quickly creating a spider’s web of interdependencies.
Consider the relatively simple infrastructure diagram below. Each application has an application database containing both user data that’s generated and used by the application and application-specific data. For example, the Applicant Tracking System (ATS) would likely contain job descriptions, hiring manager information, and interview details, as well as a lot of sensitive candidate information like resumes, names, email addresses, etc.
To support analytics and the aggregation of data among these various applications, data is copied downstream to a data lake and warehouse. There are likely multiple copies of each user’s email address and other PII being generated independently from each application.
 A Simplified Application Infrastructure
A Simplified Application Infrastructure
Over time, more applications will become part of the infrastructure, creating more interdependencies. The talent application likely needs PII already collected by the ATS and HR app, billing needs data from the CRM system, and the machine learning application that’s used to derive business intelligence needs access to everything.

A Growing Web of Interdependencies and PII Replication
Trying to integrate point solutions like tokenization and encryption at each application layer and manage access to sensitive data quickly becomes an intractable problem. This gets even more complicated when trying to deal with regulatory requirements like data residency or data localization.
How Do You Solve the Intractable Data Privacy Problem?
Leading companies like Netflix, Apple, Google, and Shopify have addressed data privacy by pioneering the zero-trust data privacy vault – you can watch the former Head of Security/Privacy Engineering at Netflix discuss this. These companies built logically centralized vaults to isolate, protect, store, and manage the sensitive customer information that’s core to their business.
A data privacy vault is a secure, isolated database designed to store, manage and use sensitive data. Similar to how you might keep important physical documents like your birth certificate, social security card, and passport in a safe in your home and not in your kitchen junk drawer with your batteries, sensitive user data should be kept separate from application data. By isolating and treating PII differently from other data, the vault becomes the single source of truth across the entire company’s infrastructure.
Features of a Data Privacy Vault
Isolation of sensitive data is just part of the story and the value that a data privacy vault provides. There are a number of other features required to create a comprehensive privacy solution. The following list breaks down the primary features that are essential to creating a data privacy vault:
- Security: Encryption, tokenization, and data masking all need to be native to the vault infrastructure in order to make sure sensitive data is properly secured.
- Isolation: The vault must be in a segregated network with privileged access. Audit logging must be built-in to track access. Additionally, isolation is required to meet compliance requirements like data residency.
- Database: The vault must have standard database functionality. It needs to be as easy to use and build with as a standard database, easing integration with existing infrastructure.
- Enterprise-Grade Reliability: The vault is critical infrastructure for a business, so it needs high availability and throughput.
- ACL Management: The vault needs native data governance, and zero trust architecture. And, it needs to let administrators control both programmatic and user access on a table-level, column-level, and row-level basis.
- Flexible Use Case Support: The vault must support both structured and unstructured data, and be flexible enough to support a broad range of use cases.
- Data Utility: The vault needs to support the authorized use of sensitive data, delivering high data utility while also enforcing strong security. So, it must support privacy-preserving analytics and secure cloud functions on sensitive data.
Fitting the Data Privacy Vault Into Your Stack
With the data privacy vault, sensitive user data is now stored separately from application data. This means that when an application needs to read sensitive data, like a customer’s email address, the application must get that information from the vault rather than the application database.
In the diagram below, the application retrieves data from both the vault and the data storage and processing layers. Instead of the application storage containing plaintext PII, it can store tokenized PII to maintain existing schemas or data pipelines.
Third-party services like payments, email, or messaging will likely need access to sensitive data like a customer’s credit card information or phone number. Secure functions from the vault pass the sensitive data to these services without the raw plain text values ever hitting your application backend, reducing your compliance burden and the risk of a breach.

Integration of a Data Privacy Vault into an Existing Stack
Additionally, programmatic permissions into the vault depend on what information the application function actually needs. As an example, in the image below, based on the ABAC/RBAC/PBAC permissions, different services see different representations of the same record.
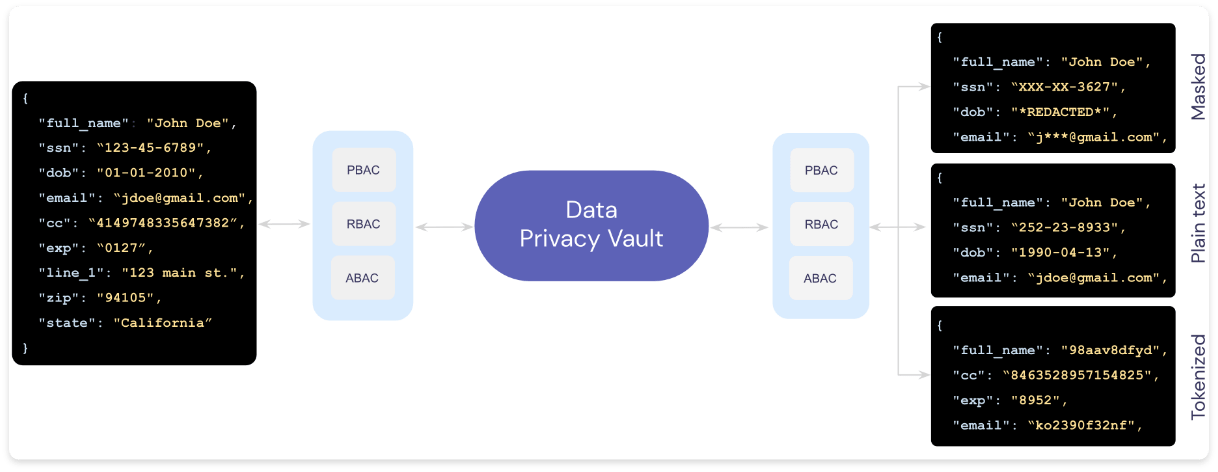
Example of Reading Data from a Vault Depending on Application Requirements
This way, a billing application that only needs the customer’s name, mailing address, credit card expiration date, and the last four digits of the credit card number only has access to exactly that information – and nothing else. Even if someone stole the application credentials, they’d only be able to see a limited amount of data, significantly reducing the scale of a data breach.
Addressing the Interdependency Problem
Returning to the interdependency problem previously discussed, by introducing a data privacy vault into that business’s infrastructure, we can significantly reduce the complexity of implementing effective customer data privacy.
As shown below, all applications now depend on a single API layer for sensitive data. Each application can have its own application-specific policies that determine what sensitive data it has access to and how it displays that data: plain text, masked, redacted, tokenized, or some combination of these.

Simplifying the PII Interdependency Problem
Solving Data Privacy
Leading companies are solving data privacy with a zero-trust data privacy vault architecture. Data privacy vaults are recognized as the best-of-breed solution for solving data privacy and related issues like security and regulatory compliance. Despite this, they haven’t made it into the lexicon of most engineers.
This is in part due to the failure of most companies to prioritize user data privacy until it’s already been compromised, and then try to apply point solutions to deal with the problem. Additionally, most companies lack the expertise and resources needed to build a data privacy vault – they’re expensive and difficult to build. It took Shopify three years and 94 contributors to build a vault to clean up their data pipelines. Most companies don’t have those kinds of resources to dedicate to this problem.
That’s why we built Skyflow, a data privacy vault delivered as an API that serves as an all-in-one privacy solution. Give us a try for free






