Is Your Microservice a Distributed Monolith?
Your team has decided to migrate your monolithic application to a microservices architecture. You’ve modularized your business logic, containerized your codebase, allowed your developers to do polyglot programming, replaced function calls with API calls, built a Kubernetes environment, and fine-tuned your deployment strategy. But soon after hitting deploy, you start noticing problems. Services take a […]
Your team has decided to migrate your monolithic application to a microservices architecture. You’ve modularized your business logic, containerized your codebase, allowed your developers to do polyglot programming, replaced function calls with API calls, built a Kubernetes environment, and fine-tuned your deployment strategy. But soon after hitting deploy, you start noticing problems. Services take a long time to start, failures cascade from one container to the next, and small changes involve redeploying the entire application. Weren’t microservices supposed to solve these problems?
If this sounds familiar, you might have fallen into a common microservice anti-pattern: the distributed monolith. In this article, we’ll explain what a distributed monolith is, why you should avoid them, and how you can use Chaos Engineering to validate whether your application falls under this anti-pattern.
What is a distributed monolith, and why is it bad?
A distributed monolith is an application that’s deployed like a microservice but is built like a monolith. It leverages platforms like Kubernetes and a distributed systems architecture but isn’t designed to do so efficiently or reliably.
In a monolithic architecture, the entire application is bundled into a single package that includes source code, libraries, configurations, and all other dependencies required for it to run. Monoliths aren’t inherently bad, but they have limitations:
- Deployment artifacts are typically large, slow to start, and use a significant chunk of resources.
- Changing one part of the application means rebuilding and redeploying the entire application, slowing developer productivity.
- Scaling horizontally is inefficient, as monoliths aren’t inherently designed for distributed systems.
In comparison, microservices split an application into discrete units that have clearly defined service boundaries, are less resource-intensive, and are more readily scalable. These benefits come at the cost of deployment complexity, managerial overhead, and observability challenges. Besides managing our application, we now need to manage images and containers, orchestration tools, networking and security policies, distributed data, and more.
With a distributed monolith, we have the heaviness and inflexibility of monoliths, the complexity of microservices, and few of the benefits of either architecture. We still have slow deployments and poor scalability, but now we’ve added operational complexity and removed isolation between services. Our engineers need to learn the new architecture, adopt new tooling, and rebuild their applications to tolerate the dynamic and transient world of containers, adding tons of time and labor.
How can you tell whether your microservice is a distributed monolith, and what does this mean for your development strategy and application reliability? We’ll list some common characteristics of this anti-pattern and show you how you can test for them by using Chaos Engineering.
Sign #1: Services are tightly coupled
Coupling refers to the degree of separability between two functions. In a monolith, different functions are tightly coupled due to sharing a common code base and running within the same process space. Tight coupling can take different forms, such as:
- Requiring a dependency to be available to complete a task (behavioral coupling).
- Requiring fast, low-latency communication with other services (temporal coupling).
- Having to change multiple services as a consequence of changing a single service (implementation coupling).
Think of an e-commerce application. When a customer views a product page, we need to:
- Query the database for information about the product.
- Process that information on the backend.
- Render it on the page.
Using a traditional monolithic application, we might create a model-view-controller (MVC) framework to logically separate our backend logic (retrieving product details) from our frontend logic (rendering the web page). These are two different functions developed by two different development teams, but they’re part of the same monolithic codebase. We can’t deploy or modify one without doing the same to the other.
Now let’s restructure this application as a microservice. We’ll create two services: one for the frontend and another for the product catalog. We’ll replace direct function calls with API calls and connect the services over the network. Everything looks and works great, but then our product catalog service crashes. What happens to the frontend? Does it continue working despite the failure, or are our services so tightly coupled that the frontend also fails? If our backend team deploys a fix to the product catalog, do we also need to deploy a fix to the frontend? Most importantly, what does the customer experience when this happens?
How do you test for tight coupling?
When testing for tight coupling, we need to determine whether changing the state of one service affects another service. To demonstrate this, we’ll use an open-source microservice-based e-commerce website called Online Boutique. Online Boutique uses ten distinct services to provide features such as the frontend, payment processing, and shopping cart management. We want to validate whether the product catalog is decoupled from the frontend.
We’ll perform this test using Gremlin, an enterprise SaaS Chaos Engineering platform. We’ll create a chaos experiment, which is an intentional, proactive injection of harm into a working system to test its resilience with the goal of improvement. By deliberately causing failure in the product catalog service and observing the impact on the frontend, we’ll know how tightly coupled or loosely coupled these services are.
Chaos experiments have four components: a hypothesis (what we think will happen during the experiment), an attack (the method of injecting harm), abort conditions (when to halt the test to avoid unintended harm), and a conclusion based on our hypothesis. Our hypothesis is this: if the product catalog is unavailable, the frontend displays an error message to the user. We’ll use a blackhole attack to drop all network traffic between the frontend and product catalog services. While the attack is running, we’ll refresh the web page in a browser. We’ll abort the test if the website crashes or takes more than 60 seconds to load.
Let’s run the attack in the Gremlin web app:
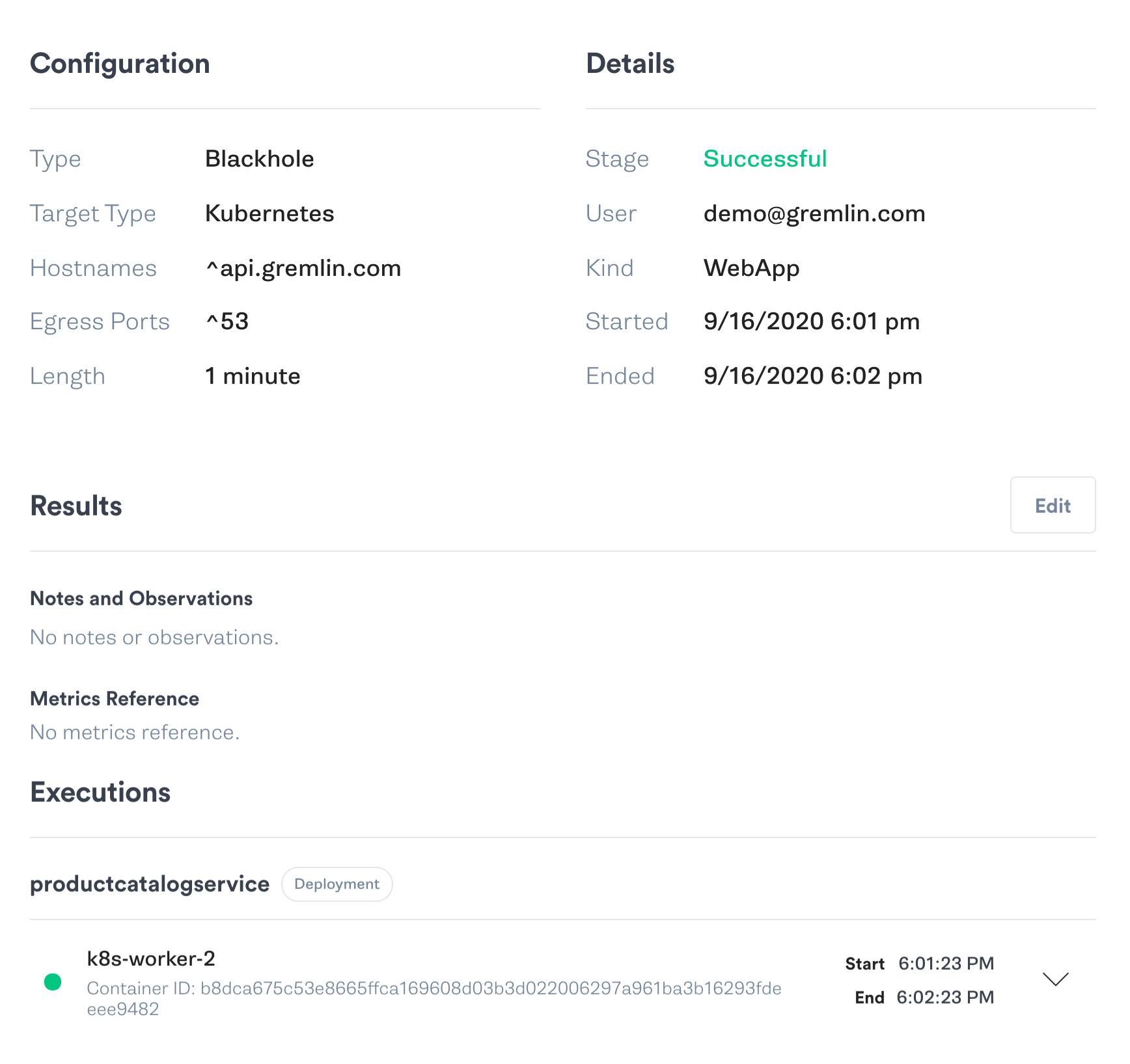
When we refresh the product page, we see that it gets stuck in a loading state. Looking at the source code shows a timeout period of 3 seconds, but our observations prove otherwise. We’ve just discovered an unintended temporal coupling and should focus on decoupling these services.
We can take quick steps to mitigate this by lowering the timeout threshold or by making our API calls asynchronous so that our frontend doesn’t have to wait on the product catalog before responding to the user. We can reduce the risk of tight coupling in other services by using domain-driven design (DDD) to set well-defined boundaries between microservices (known as bounded contexts). This step is best performed before starting a migration to microservices, but it’s still beneficial even after development has started.
Sign #2: Services don’t scale easily
Scalability is one of the most important qualities of a microservice. Being able to scale quickly and efficiently lets us handle sudden changes in demand, prevent our systems from being overloaded, and keep our operating costs low. Vertical scaling works up to a certain point, but modern cloud-native applications must also be able to scale horizontally. Cloud platforms and orchestration tools have simplified scaling, but we still need to design our applications with scalability in mind. Distributed monoliths are technically scalable, but only in very inefficient ways.
Let’s say that our website is seeing a surge in traffic, and we need to horizontally scale our frontend to handle the increased number of connections. With a monolith, we need to deploy new instances of the full application and all of its dependencies. Not only is this process complex and prone to failure, but it takes longer and uses resources less efficiently than with a true microservice.
When testing for a distributed monolith, we want to know how long it takes our application to scale, what the potential failure points are while scaling, and what impact this has on other services (specifically, dependencies).
How do you test for scalability?
For this test, we’ll deploy WordPress, an open-source CMS, to a Kubernetes cluster using the Bitnami Helm chart. This chart deploys the WordPress application in one Pod, and its attached MariaDB database in another Pod. We’ll create auto-scaling rules to increase the number of WordPress Pods when CPU usage exceeds 50% utilization across the deployment:
BASH 1helm repo add bitnami https://charts.bitnami.com/bitnami 2helm install wordpress bitnami/wordpress 3kubectl autoscale deployment wordpress –cpu-percent=50 –min=1 –max=10
Note that this only scales the WordPress application, not MariaDB. This means that all of our newly-provisioned Pods will attach to the same data store. When testing scalability, we want to see:
- Whether our application can scale and load balance traffic reliably.
- How long it takes for the new Pod to get up and running.
- Whether MariaDB acts as a bottleneck.
We’ll do this by using a CPU attack to increase CPU usage on the deployment. We’ll set our target utilization to 60% while monitoring the state of the deployment using kubectl.
BASH 1watch -n 1 ‘kubectl get hpa wordpress’ 2 3NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE 4wordpress Deployment/wordpress <unknown>/50% 1 10 1 3m54s
Note how long it takes for the new Pods to deploy. Once traffic is load balanced to the new Pods, monitor the amount of load on your database. Is there a significant enough increase to where you need to scale up your database as well? If so, you may have a distributed monolith.
This is a useful experiment regardless of whether you think your application is a monolith as it can help you prepare for traffic spikes and maintain high rates of throughput during unexpected load.
Sign #3: Services are overly chatty
Sharing data between distributed systems is challenging due to the added latency of network calls. In a monolith, data can flow between functions nearly instantaneously. But in a microservice, extensive communication between services will significantly reduce the application’s throughput, possibly causing timeouts and other unexpected failures.
For example, WordPress uses a MySQL (or MariaDB) database to store data such as user accounts, page contents, configuration settings, and much more. A single page load can generate multiple MySQL queries. As such, WordPress works best with a low-latency (ideally local) database connection, but this creates a temporal dependency between the two services.
In Kubernetes, one option is to deploy WordPress and MySQL together in the same Pod. But this creates a Pod that serves multiple functions, requires significant system resources, has a longer startup time, requires data replication and synchronization, and is owned by both the application and database team. In other words, it’s a monolith packaged as a microservice.
Networking two services might not seem like a problem until our network becomes saturated or degraded. With Chaos Engineering, we can see the impact that this might have on our application.
How do you test for chatty services?
Imagine that a network error is adding 20 ms of delay to all network traffic in our environment. This doesn’t seem like much, and a well-architected microservice should be able to tolerate this with only a minor increase in response time.
Using Gremlin, we’ll use a latency attack to add 20 ms of latency between our WordPress Pod and its MySQL Pod. We’ll use Apache Bench to benchmark response times before and during the attack.
First, let’s get our baseline metrics before running the attack. We see that each request takes roughly 128 ms to complete:
BASH 1$ ab -t 30 http://kubernetes-cluster:30003/ 2Requests per second: 7.78 [#/sec] (mean) 3Time per request: 128.549 [ms] (mean) 4Time per request: 128.549 [ms] (mean, across all concurrent requests) 5Transfer rate: 197.97 [Kbytes/sec] received
Now, let’s run the attack. Once the attack enters the Running state, we’ll re-run the benchmark:
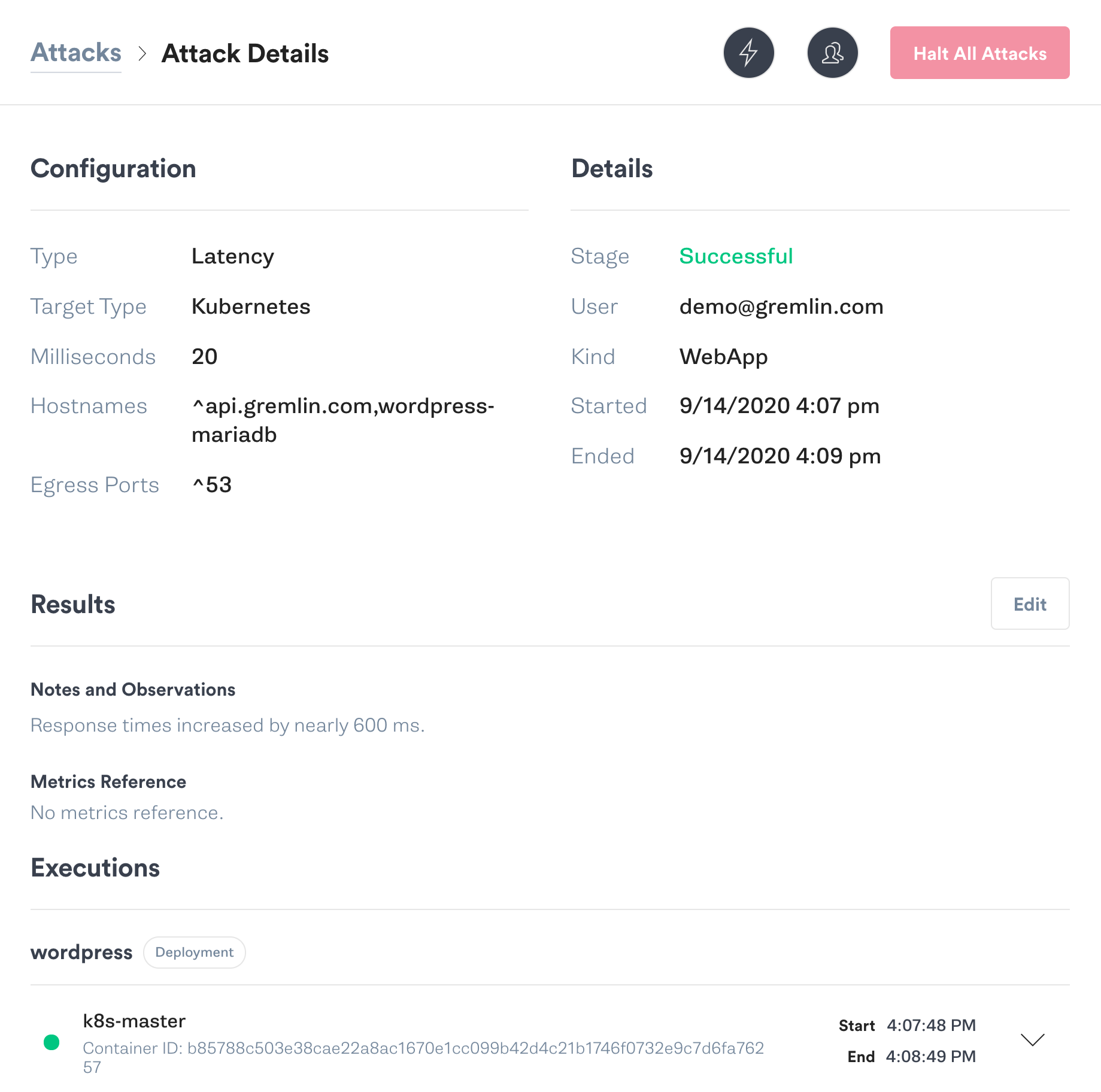
BASH 1$ ab -t 30 http://kubernetes-cluster:30003/ 2Requests per second: 1.39 [#/sec] (mean) 3Time per request: 718.532 [ms] (mean) 4Time per request: 718.532 [ms] (mean, across all concurrent requests) 5Transfer rate: 35.42 [Kbytes/sec] received
Just 20 ms of additional latency caused a 5.5x increase in response time, an 82% decrease in transfer rate, and a noticeable delay for users. Almost anything could cause a similar outcome in the real world, from network saturation to a faulty switch to Kubernetes scheduling the MySQL Pod on another node. Imagine if we had a 40 ms delay, or a 100 ms delay!
To mitigate the effect of latency, reduce the number of round-trip network calls between services. Consider making calls asynchronous, or using a message queue like Apache Kafka to decouple these services. As with tight coupling, this is another good example of why you should use domain-driven design to split your services and data into different domains.
Conclusion
Moving to microservices involves more than just repackaging monolithic applications into containers. There are fundamental differences in architecture that affect everything from how we transfer data to how we recover from failures. Failing to account for these differences can lead to restricted scalability, diminished performance, and unexpected outages.
To determine whether your application is a distributed monolith, sign up for a Gremlin Free account and start running experiments on your applications within minutes. Use the CPU attack to test your application’s ability to auto-scale, or use a shutdown attack to test for tight coupling between services.


