LinkedIn Kafka
This article is part 2 in a series about LinkedIn’s data journey. You can read the first part of LinkedIn’s data infrastructure here. It requires repeating that LinkedIn is a massive player in the software industry, in terms of the number of active users and website interactions. With a user base of over 675 million […]
This article is part 2 in a series about LinkedIn’s data journey. You can read the first part of LinkedIn’s data infrastructure here.
It requires repeating that LinkedIn is a massive player in the software industry, in terms of the number of active users and website interactions. With a user base of over 675 million people and growing, the challenges LinkedIn engineers face in terms of the sheer amount of data are on a scale not commonly experienced in the industry. Over the years, these challenges have paved the way for various innovative methodologies and tools. Out of the tools that came from LinkedIn developers, the most famous one is Kafka.
Kafka forms the backbone of operations at LinkedIn. Most of the data communication between different services within the LinkedIn environment utilizes Kafka. It is used explicitly in use cases like database replication, stream processing, and data ingestion.
What is Kafka?
Before going into the details of how Kafka can be used in scale and how it actually is used in LinkedIn, we’ll first give a brief description of what Kafka is, and how it works.
Kafka is a distributed streaming platform. This definition might be abstract, but it captures the core capabilities of Kafka: it is a platform dealing with streaming data as a distributed system. Streaming data is data that is constantly being generated by possibly numerous sources, continuously ordered in time, in contrast with what we might call batch data, which can be historical data that is usually stored in databases.
Kafka deals with records. A record is a single unit of information, a collection of bytes. It can have metadata as its key. Records that are produced for the same topic and partition are bundled in batches to reduce network latency costs.
Kafka handles this type of data with the concept of topics, which are in essence distributed commit logs that act as message queues. A producer writes data into topics, which can be partitioned and replicated for scalability and fault tolerance. Each partition in the topic is essentially a commit log, an append-only, time-ordered data structure.
Each Kafka server is called a Kafka broker. It deals with the storing of data being produced by the producers in disk, and serving requests of consumers. Multiple Kafka brokers come together to form Kafka clusters.
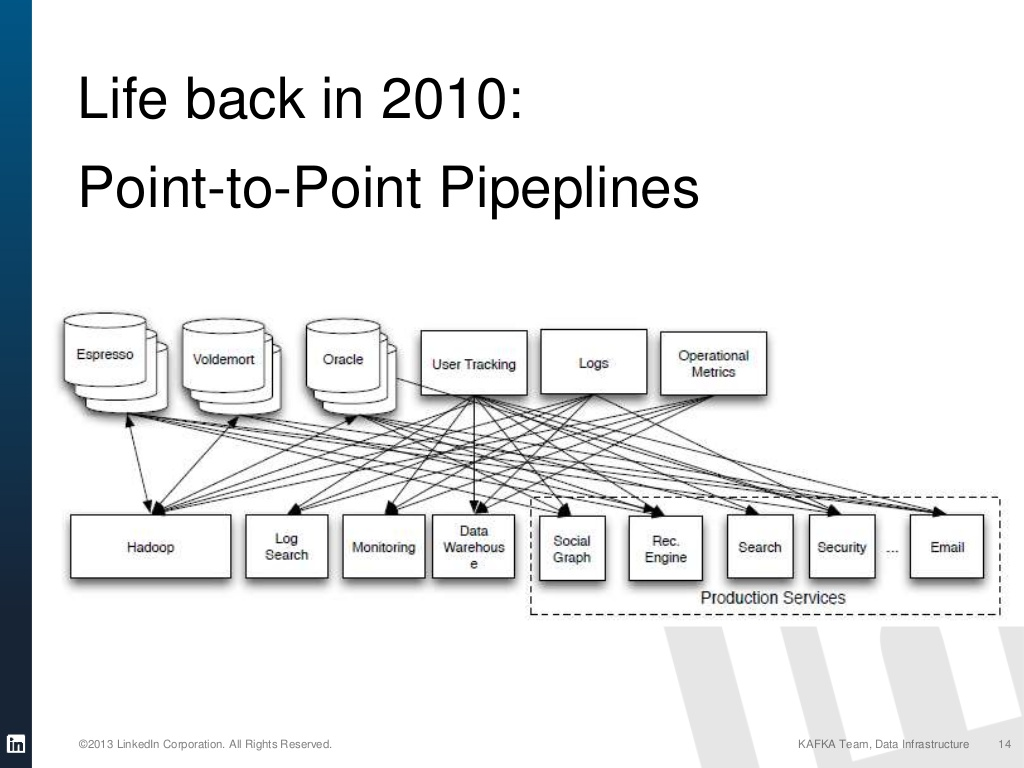
The need for Kafka comes from decoupling any direct links between processes that produce the data, and services that analyze or consume the data. The direct links can get confusing and would require a coordinated effort from multiple teams of frontend and backend. The same piece of data can be utilized in a wide variety of tasks, and correspondingly might require it to be preprocessed in different ways into different formats.
Kafka solves these problems using a push-pull model that lets producers push data into topics and lets consumers pull data whenever they need to. By allowing persistence within the topics, instead of records disappearing once they are consumed, Kafka allows multiple consumers to read data from the same topic. Built with topics and partitions, Kafka is horizontally scalable for the varying needs of numerous organizations.

There is a whole ecosystem built around Kafka at LinkedIn
Kafka was originally designed to facilitate activity tracking, and collect application metrics and logs at LinkedIn. Currently, messages being relayed by Kafka are divided into five main sections, namely: queueing, metrics, logs, database replication, and tracking data.
Kafka brokers facilitate message queues between different applications and services. This process is done in a streaming fashion, as the new data gets added to topics continuously. In the past, storing this data in Hadoop to perform batch processing was enough for most use cases. However, as online services evolved, performing high-latency data processing gave way to low-latency to enable possibly near-time processing solutions. From detecting congestion and unusual traffic to changing recommendations for users following an action, near-time processing use cases have become a necessity for online platforms.
At LinkedIn, to connect the distributed stream messaging platform, Kafka, to stream processing, Samza was developed and later became an incubator project at Apache. Apache Samza is a distributed stream processing system that relies on the concept of streams and jobs operating on these streams. For LinkedIn’s operations that require near real-time response, streams are facilitated by Kafka and the processing is done by Samza. By delegating jobs that normally would be done with Map/Reduce jobs in Hadoop to Samza, LinkedIn engineers can provide a rich user experience and make real-time decisions in the case of an anomaly.
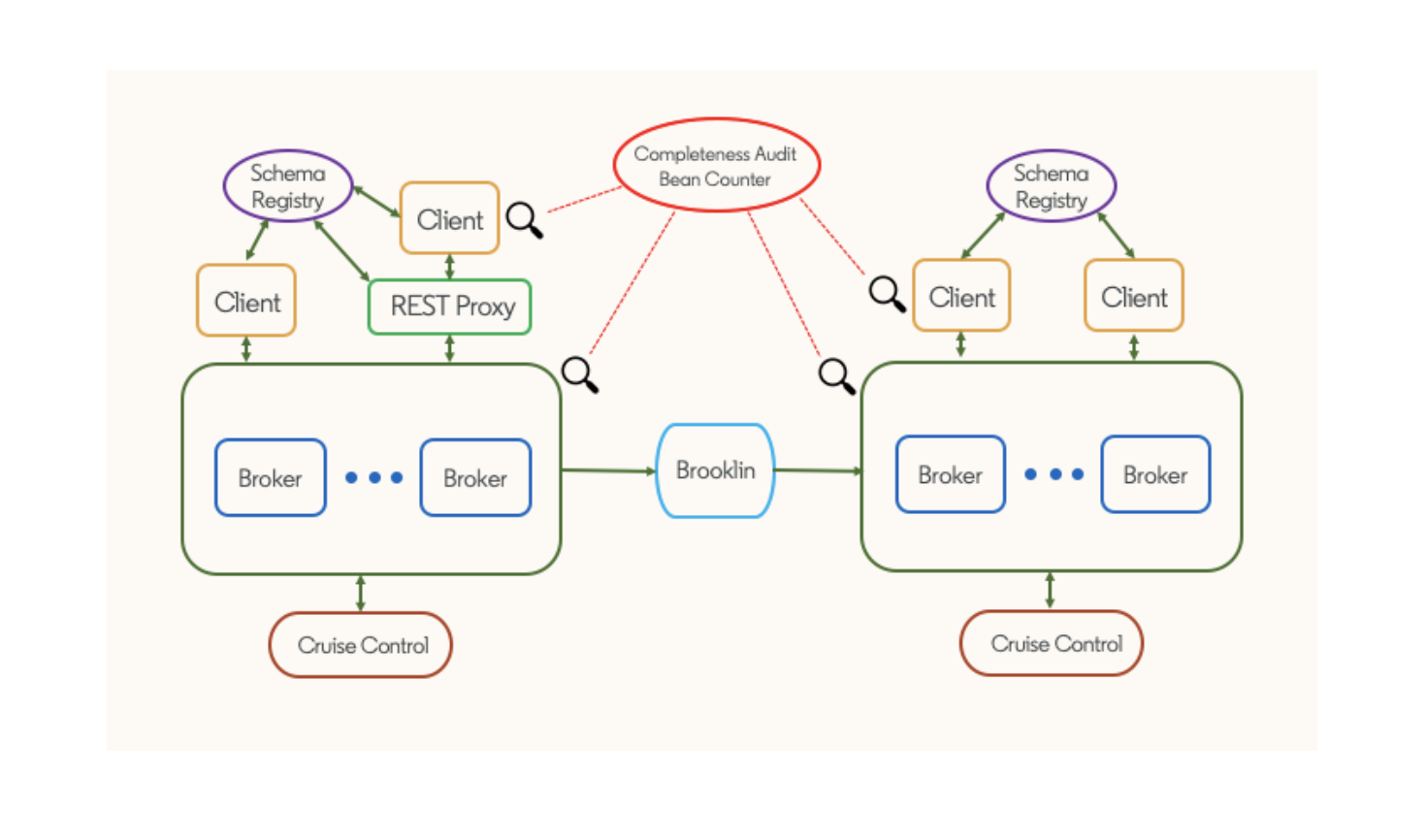
Real-time processing does not always have to rely on data that has been recently created. Streams can be created from historical and static data, depending on the use case. To this end, LinkedIn has developed and open-sourced Brooklin, a distributed streaming service that can consume data from diverse sources and produce streams for other applications to use. Brooklin focuses on data movement. It can be seen as a streaming bridge that can move data across different environments, including different public clouds, databases, and messaging systems. As you can draw the parallel, Brooklin can both be a consumer and a producer for Kafka topics.

That being said, not all use cases call for near real-time responses. Batch processing is still common and valuable. Batch processing at LinkedIn is performed using Apache Hadoop.
Gobblin, a library developed by LinkedIn and later donated to the Apache Foundation, is a data integration framework that bridges the gap between multiple data sources with different data types and Hadoop. Gobblin is used as LinkedIn for this exact purpose: to ingest data that does not require immediate processing into the data lake. Since virtually all data passes through Kafka, it is one of the main sources for Gobblin’s data ingestion.
Besides the tools that are directly connected with data that goes through Kafka, LinkedIn has developed numerous tools for working with Kafka, that serve use cases like monitoring and dealing with operational challenges that come with scaling. If you look at LinkedIn’s repositories in Github, you can see that a number of them relate to Kafka.
For example, Kafka Cruise Control is an open-source tool that automates managing Kafka clusters to achieve certain end goals in terms of performance. On top of Cruise Control, LinkedIn has open-sourced Cruise Control Frontend, a visual dashboard that further simplifies managing Kafka deployments with an intuitive UI.
There are numerous more tools, like Kafka Monitor and Burrow, that are actively used in LinkedIn and open-sourced for the Kafka community. This whole ecosystem shows the importance of Kafka to LinkedIn’s operations, and how dedicated they are to pushing the limits of Kafka to new horizons.
LinkedIn as a developer of Kafka
LinkedIn, as the main contributor to Kafka, has an internal Kafka development team that is a reliable contact point within the company for any Kafka-related support needs. Relying heavily on Apache Kafka, LinkedIn keeps internal release branches that have been branched off separate from upstream Kafka. Since the ecosystem around Kafka is vast and the amount of data that pours into their operations is on a very large scale, LinkedIn maintains its own releases to address the scalability and operability issues. This branch of Kafka has recently been open-sourced on Github.
Kafka forms the backbone of LinkedIn’s stack, just as it is used by many other organizations and developers daily. LinkedIn has a great influence over Kafka as the initial developer of the tool and has helped shape the ecosystem around it. This level of commitment from a company as large as LinkedIn speaks volumes for the value of Apache Kafka.



