

Walking the Wire: Mastering the Four Decisions in Microservices Architecture


credit: Wiros from Barcelona, Spain
This post was originally written by Srinath Perera on Medium. Reposted with permission.
Microservices are the new architectural style for building systems using simple, lightweight, loosely coupled services that can be developed and released independently of each other.
If you need to know the basics, read Martin Fowler’s Post. If you like to compare it with SOA, watch Don Ferguson’s talk. Also, Martin Fowler has written about “trade-off of microservices” and “when it is worth doing microservices”, which let you decide when it is useful.
Let’s say that you heard, read, and got convinced about microservices. If you are trying to follow the microservices architecture, there are few practical challenges. This post discusses how you can handle some of those challenges.
Decision 1: Handling No Shared Database(s)

Each microservice should have its own databases and Data MUST not be shared via a database. This rule removes a common case that leads to tight coupling between services. For example, if two services share the same database, the second service will break if the first service has changed the database schema. So teams will have to talk to each other.
I think this rule is a good one, and should not be broken. However, there is a problem. If two services share the same data (e.g. bank account data, shopping cart) and need to update the data transactionally, the simplest approach is to keep both in the same database and use database transactions to enforce consistency. Any other solution is hard.
Solution 1: If updates happen only in one microservice (e.g. loan approval process check the balance), you can use asynchronous messaging (message queue) to share data.

Solution 2: If updates happen in both services, you can either consider merging the two services or use transactions. The post Microservices: It’s not (only) the size that matters, it’s (also) how you use them describes the first option. The next section will describe the transactions in detail.
Handling Consistency of Updates
You will run into scenarios where you will update the data from multiple places. We discuss an example in the earlier section. ( If you update the data only from one place, we already discussed how to do it).
Please note this use case typically solved using transactions. However, you can sometimes solve the problem without transactions. There are several options.
Option 1: Put all updates to the same Microservice
When possible, avoid multiple updates crossing microservice boundaries. However, sometimes by doing this, you might end up with few or worse one big monoliths. Hence, sometimes, this is not possible.
Option 2: Use Compensation and other lesser Guarantees
As the famous post “Starbucks Does Not Use Two-Phase Commit” describes, the normal world works without transactions. For example, the barista at Starbucks does not wait until your transaction is completed. Instead, they handle multiple customers same time and compensate for any erroneous conditions explicitly. You can do the same, given you are willing to do a bit more work.
One simple idea is if an option failed, you go and compensate. For example, if you are shipping the book, first deduct the money, then ship the book. If the shipping failed, you go and return the money.
Also, sometimes you can settle for eventual consistency or timeout. Another simple idea is to give a button to the user to forcefully refresh the page if he can tell that it is outdated. Some other times, you bite the bullet and settle for lesser consistency (e.g. Vogel’s post is a good starting point).
Finally, Life Beyond Distributed Transactions: An Apostate’s Opinion is a detailed discussion on all the tricks.
Having said that, there are some use cases where you must do transactions to get correct results. And those MUST use transactions. see Microservices and transactions-an update. Weigh the pros and cons and choose wisely.
Decision 2: Handling Microservice Security
Old approach is the service to authenticate by calling the database or Identity Server when it has received a request.
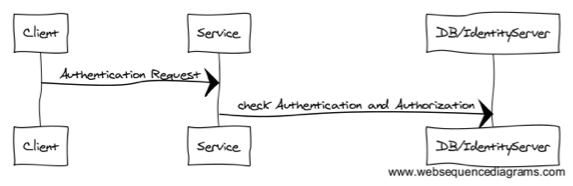
You can replace the identity server with a microservice. That, in my opinion, leads to a big complicated dependency graph.
Instead, I like the token-based approach depicted by the following figure. The idea is described in the book, “Building Microservices”. Here the client ( or a gateway) would first talk to an identity/SSO server who will authenticate the user and issue a signed token that describes the user and his roles. (e.g. you can do this with SAML or OpenIDConnect). Each microservice verifies the token and authorizes the calls based on the user roles described in the token. For example, with this model, for the same query, a user with role “publisher” might see different results than a user with role “admin” because they have different permissions.

You can find more information about this approach from How To Control User Identity Within Microservices?.
Decision 3: Handling Microservice Composition
Here, “composition” means “how can connect multiple microservices into one flow to deliver what end-user needs”.
Most compositions with SOA looked like following. The idea is that there is a central server that runs the workflow.

Use of ESB with microservices is discouraged (e.g. Top 5 Anti-ESB Arguments for DevOps Teams). Also, you can find some counter arguments in Do Good Microservices Architectures Spell the Death of the Enterprise Service Bus?
I do not plan to get into the ESB flight in this post. However, I want to discuss whether we need a central server to do the microservices composition. There are several ways to do the microservices composition.
Approach 1: Drive flow from Client
The following figure shows an approach to do microservices without a central server. The client browser handles the flow. The post, Domain Service Aggregators: A Structured Approach to Microservice Composition, is an example of this approach.
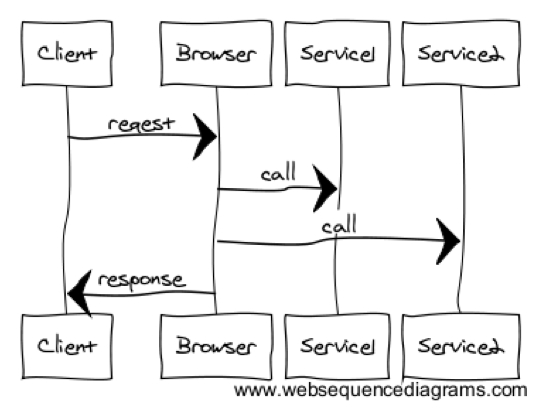
This approach has several problems.
- If the client is behind a slow network, which is the most common case, the execution will be slow. This is because now multiple calls need to be triggered by the client.
- Might add security concerns ( I can hack my app to give me a loan)
- Above example thinks about a website. However, most complex compositions often come from other use cases. So general applicability of composition at the client to other use cases yet to be demonstrated.
- Where to keep the State? Can the client be trusted to keep the state of the workflow? Modeling state with REST is possible. However, it is complicated.
Approach 2: Choreography
Driving the flow from a central place is called orchestration. However, that is not the only way to coordinate multiple partners to carry out some work. For example, in a dance, there is no one person directing the performance. Instead, each dancer would follow who is near to her and sync up. Choreography applies the same idea to businesses process.
Typical implementation includes an eventing system, where each participant in the process listens to different events and carries out his or her parts. Each action generates asynchronous events that will trigger participants down the stream. This is the programming model used by environments like RxJava or Node.js.
For example, let’s assume that a loan process includes a request, a credit check, other outstanding loans check, manager approval, and a decision notification. The following picture shows how to implement this using choreography. The request will be placed in a queue. It will be picked up by the next actor, who will put his results in the next queue. The process will continue until it has completed.

Just like a dance needs practice, the choreography is complicated. For example, you did not know when the process has finished, nor you will know if an error has happened, or if the process is stuck. Choreography needs a monitoring system to track progress and recover or notify about the error.
On the other hand, the advantage of choreography is that it creates systems that are much loosely coupled. For example, often you can add a new actor to the process without changing other actors. You can find more information from Scaling Microservices with an Event Stream.
Approach 3: Centralized Server
The last but most simple option is a centralized server (a.k.a orchestration).
SOA’s implemented this often using two methods: ESB or Business Processes. Microservice folks propose an API Gateway (e.g. Microservices: Decomposing Applications for Deployability and Scalability). I guess API gateway is more lightweight and use technologies like REST/JSON. However, in a pure architectural sense, all those uses orchestration style.
Another variation of the centralized server is “backend for frontends” (BEF), which build a server-side API per client type ( one for desktop, one for iOS etc). This model creates different APIs per each client type, optimized for each use case. See the pattern: Backends For Frontends for more information.
I would suggest not to go crazy with all options here and start with the API gateway as that is the most straightforward approach. You can switch to more complicated options as the need arises.
Decision 4: Avoiding Dependency Hell
We do microservices to make it possible that each service can release and deploy independently. To do that, you must avoid the dependency hell.
Let’s consider microservices “A” who has the API “A1” and have upgraded to API “A2”. Now there are two cases.
- Microservice B might send messages intended for A1 to A2. This is backward compatibility.
- Microservice A might have to revert back to A1, and microservices C might continue to send messages intended to A2 to A1.
You must handle above scenarios somehow, and let the microservices evolve and deployed independently. If not, all your effort will be wasted.
Often, handling these cases is a matter of adding optional parameters and never renaming or removing existing parameters. More complicated scenarios, however, are possible.
The post “Taming Dependency Hell” within Microservices with Michael Bryzek discuss this in detail. Ask HN: How do you version control your microservices? is also another good source.
Finally, backward and forward compatibility support should be bounded by time. For example, you can have a rule that no microservice should depend on APIs that are more than three months old. That would let the microservices developers to eventually drop some of the code paths.
Finally, I would like to rant a bit about how your dependency graph should look like in a microservices architecture.
One option is freely invoking other microservices whenever it is needed. That will create a spaghetti architecture from the pre-ESB era. I am not a fan of that model.
The other extreme is saying that microservices should not call other microservices and all connection should be done via API gateway or message bus. This will lead to a one level tree. For example, instead of the microservice A calling B, we bring result from the microservice A to the gateway, which will call B with the results. This is the orchestration model. Most of the business logic will now live in the gateway. Yes, this makes the gateway fat.
My recommendation is either to go for the orchestration model or do the hard work of implementing choreography properly. Yes, I am asking not to do the spaghetti.
Conclusion
The goal of Microservices is loose coupling. Carefully designed microservice architecture let you implement a project using a set of microservices, where each is managed, developed, and released independently.
When you designed with microservices, you must keep the eye on the prize, which is “loose coupling”. There are quite a few challenges and this post answer following questions.
- How can I handle scenario that needs to share data between two microservices?
- How can I evolve microservices API while keeping loose coupling?
- How to handle security?
- How to compose microservices?
Thanks! love to hear your thoughts.
If you enjoyed this post you might also find the following interesting.
Also, check out some of my most read posts and my talks (videos). Talk to me at @srinath_perera or find me.






