

Converged Data Platform: Unifying Streaming Data using MapR


Stream processing and distributed database management are concerns that most enterprises dealing with data analytics and real-time data processing have. Most enterprises today use data to keep an edge over the competition. Managed data platform services make it easier for enterprises to manage their data in a highly available, distributed fashion in the cloud.
Big Data Across the Web
The amount of data generated and processed by computers today is huge. There are almost four billion Internet users, generating data with each Google search, each Tweet, and each Instagram post. On top of this human-generated data, there is data generated by machines, sensors, IoT devices, cars, planes, and more. Companies are faced with a big challenge: making sense of this much data to drive business decisions and to improve their product.
The Value of Data
Data creation and collection in itself does not make much sense if it cannot be utilized in some way to benefit the company or the users. The real value of data lies within its correct use. Each Google search and the subsequent clicked link can help Google improve its algorithms. Sensor readings from a factory can help detect anomalies, help drive future projects, and optimize their machine usage. Fraud detection in transactions must be reliable and fast to be able to take the necessary actions.
From Batch to Real-Time
Historically, data processing has been limited by the capabilities of databases. Real-time processing was hard, if not impossible. Batch processing used to be the only way to do analytics.
As commodity hardware got cheaper, it was easier to scale compute and storage which made possibly real-time data analysis with increased bandwidth and a much faster Internet. Many applications require real-time processing of data (i.e. sensors, stock trading, and healthcare). Autonomous cars require real-time feedback to calculate their next step, whether to stop or drive on. Web traffic processing and ad creation require real-time performance.
Real-time data comes in streams (continuous chunks of data), and the resulting processing was accordingly named stream processing. As opposed to traditional database interactions, where user queries the database for results, stream-based applications data is pushed to a system that must evaluate queries in response to detected events.

Why Stream Processing Is Hard
In a centralized database environment, real-time data analysis is not feasible, due to immense amounts of data pouring in. The inherent geographical variety of sources for data analysis also necessitates a distributed database system. However, a distributed database system is not easy to manage. Databases need to be queried together to perform large-scale analytics. Their communication creates performance and management problems.
Assuming there is a functional distributed database system, as a consequence of dealing with stream-based applications, distributed stream processing is born.
There are numerous complexities for stream-based applications. Both producers and consumers are connected to the Internet, so latency is a concern. Producers generate the data, such as devices or people. Consumers are the applications that act upon the data and create a response. Two other points to be considered are independence and persistence. Stream processing producers and consumers should be independent services, and this independence implies persistence. Once the data is out of the producer’s hands, it should certainly reach the consumer, since the producer is independent from the consumer side. So, fault recovery is an important feature that any stream processing framework should have.

MapR: Converged Data Platform
MapR offers a Converged Data Platform that allows a global namespace for all the files, tables, documents, and streams. It brings together all the solutions necessary to a data-driven enterprise. This platform can be on your own servers, any cloud provider, or on edge devices to provide a unified view. MapR Converged Data Platform consists of three main components, MapR FS, MapR DB, MapR Streams. These components form the basis of the platform. The platform provides APIs to numerous open source projects and integrates the essentials like Hadoop and Spark.
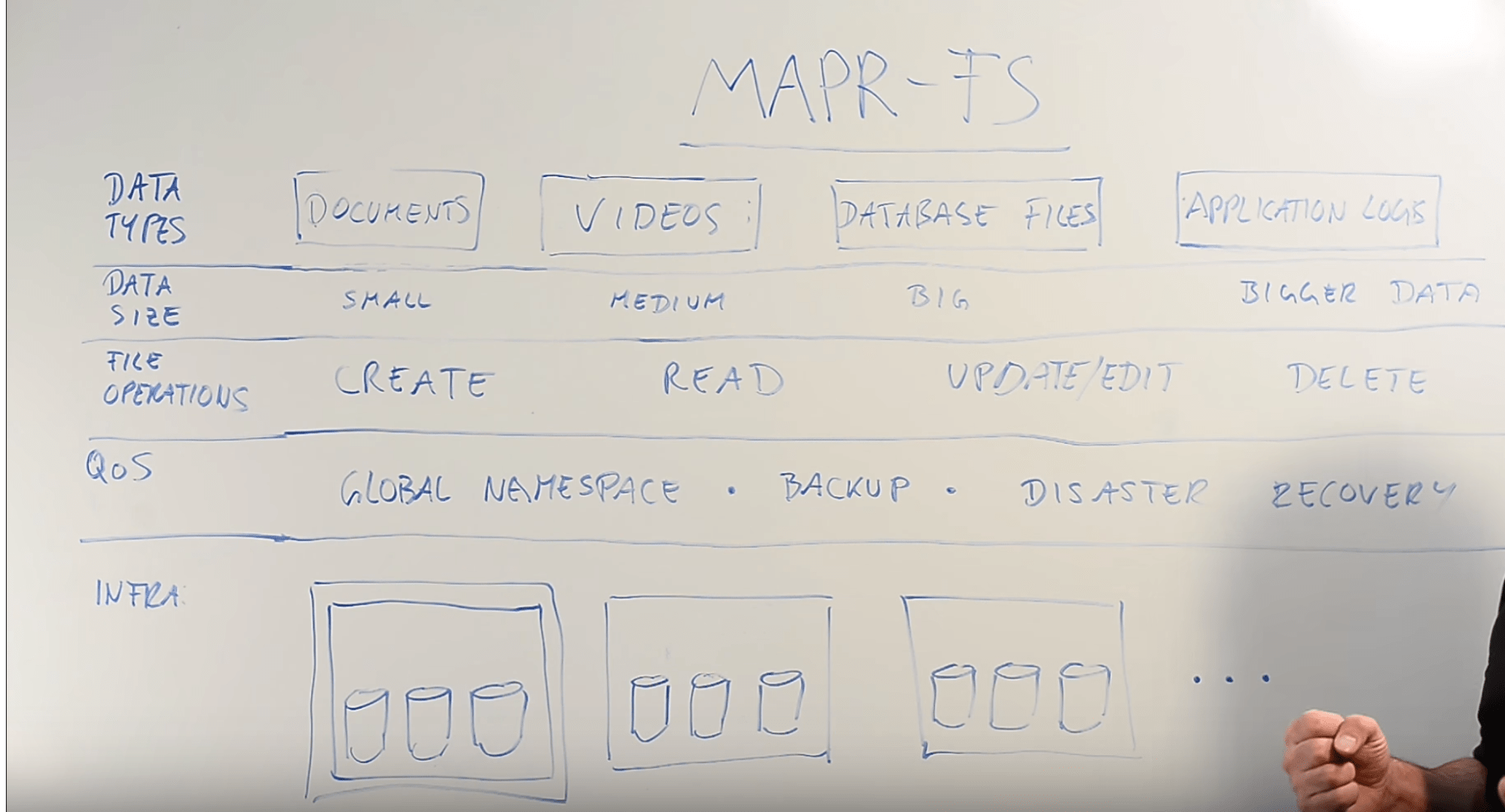
MapR File System
The standard in the industry when dealing with big data is Hadoop Distributed File System, or HDFS. Since scaling a single server by upgrading its hard disk, vertical scaling, is quite expensive, distributed file systems, horizontal scaling, with multiple servers became the norm.
However, MapR FS recognizes some deficiencies of HDFS and improves upon them. MapR introduces a Container Location Database instead of the NameNode in HDFS. Name Nodes are hard to configure, and as they are replicated so as not to become single points of failure, configuration gets even harder. Container DB is more stable, as container allocation is not changed as often as files, and takes less space.
An important concept in MapR FS is the global namespace. In MapR FS, you have an overview of your files as you would see them in local laptops or computers despite the files being distributed across many nodes.
MapR allows full read-write operations on your files, while HDFS just has append-only options. MapR offers high performance when editing, creating, and deleting files, since any update to the file does not have to be recorded in the NameNode. MapR is also optimized to make writes and reads even faster as it talks directly to disk.
To top it all off, MapR FS supports HDFS API, so you don’t have to change the code in your applications that talk to HDFS if you migrate to MapR.
MapR Database
MapR DB is high-performance NoSQL database management system. Its core values lie within scalability, reliability, and performance. MapR DB can scale easily, with automatic sharding and balancing, all without compromising its reliability and performance. It enables multi-master replication for reliability and provides extreme quick node recovery with minimal failover lag.
MapR DB supports multiple data models, so developers are not limited to one data model per database, and can choose their data models according to their use case. MapR DB has integrated MapR Streams for real-time data ingest and processing.
MapR Streams
MapR Streams runs to the rescue of applications that need real-time data processing in an efficient and reliable fashion.
Extending upon the capabilities provided by Kafka Streams MapR is fully compatible with Kafka API, meaning that you don’t have to change the application code dealing with streams if you are switching from Kafka to MapR Streams.
MapR Streams acts as the vehicle between the producer and the consumer. The consumer for real-time data analysis is usually Apache Spark or Apache Storm, which are included in MapR. MapR Streams makes sure that the correct data goes to the correct consumer and data doesn’t get lost.

A topic is a namespace for a specific type of streaming events. Producers publish to topics and consumer subscribe to the topics they care about. This pattern is called pub-sub.

MapR Streams handles the high amount of data by partitioning them into different servers. This allows huge amounts of data to be passed through the streams in a parallel manner. A concern that arises whenever there is a distributed system is load balancing for incoming requests. MapR takes care of load balancing as well to ensure high performance. These partitions are also replicated within the servers which ensure low failover time and data recovery.


Easy Management
Outside of the benefits these individual components bring, MapR Converged Data Platform has some independent features.
MapR ensures security with integrated measures; the platform is secure by design. The platform complies with regulatory standards as well.
MapR also makes management easy with Control System, monitoring, and automatic optimizations. MapR Control System provides an easy-to-use interface to the whole data and the ability to handle further management through the system or through a command line interface or via a REST API. Automatic optimizations on the database level also lower managerial efforts needed to take care of the system.
Try out MapR
MapR provides numerous advantages in terms of reducing the overhead for data management by providing fast, scalable, distributed, secure, reliable systems. All this amounts to easier operations for enterprises, faster operations and happier customers, and much lower costs. This reduction ranges between 20% and 50%.
If you want to try MapR, you can check it out here.
Resources
Computing Infrastructure for Big Data Processing
Scalable Distributed Stream Processing
Survey of Distributed Stream Processing
Streaming Architecture with Tugdual Grall
Software Engineering Daily – Streaming Architecture with Ted Dunning







