

Powering Search and Discovery at VICE


This Article was originally written by Michael Henderson on Medium. Reposted with permission from VICE Tech.
At VICE Media, we have a lot of content. At the time of writing, we have about 1.2 million articles pertaining to about 750,000 topics, created with the help of 50,000 contributors. All of this content is great to have, but when a piece of content is too old to appear on the front page, it’s essential to be able to search for it effectively. Besides being used on our sites, search is used heavily by our contributors for finding content to edit or link to. To provide this functionality to our users, we used Elasticsearch, a few AWS products, and a series of in-house microservices.
In particular, Elasticsearch made effective search so accessible to us, we began to wonder how we could use it for more than just traditional retrieval; we began exploring the possibility of using it to power content discovery. If Elasticsearch could help us match search terms to documents (articles, videos, topics, contributors, etc.), then we thought it could surely help match documents to a user’s preferences and interests. The theory is that by examining what a user likes, we can extract some data points to ‘match’ and score documents with, essentially making recommendations to the user without having to use any infrastructure besides what we already have.
Infrastructure Needs
While brainstorming these ideas, though, we realized we’d have to strengthen the tech around our existing search infrastructure before adding more functionality driven by our Elasticsearch cluster. We would definitely need a robust pipeline to carry updates over reliably and with little latency from our CMS to our Elasticsearch cluster, as well as to quickly perform a full rebuild of our search indices in case something ever goes wrong (or we decide to alter the indices’ schemas). We’d also need a maintainable way of building Elasticsearch queries in our application code to handle the inevitably more complex queries required for new features. Lastly, we’d need a framework for testing the quality of new query changes, and a method of copying down production data to local or development Elasticsearch instances for analysis.
Building (and keeping up-to-date)
We needed a quick process for rebuilding indices with zero downtime, and we needed to be able to keep our indices up to date with our CMS with minimal latency. We were able to solve both of these problems using a pair of Python scripts with the majority of the lower level logic contained in a library shared between the two, which manages a multi-threaded process to fetch records in bulk from our MySQL database, chunk the data into Elasticsearch ‘/_bulk’payloads, and submit it to the Elasticsearch cluster.
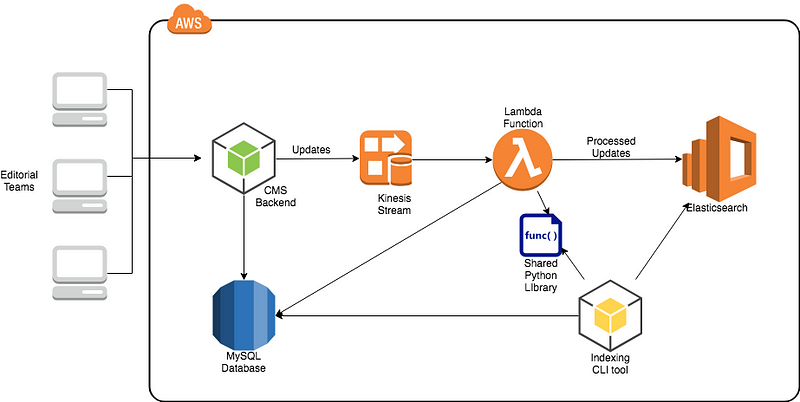
For completely rebuilding indices, we developed a CLI tool which exposes the functionality of this library. After building a fresh set of indices with unique names, a series of checks are run against the new indices, and if they pass, the aliases that our search service queries are swapped to the new set, and old indices are cleaned up.
As for keeping the indices in sync, we decided a ‘push’ model was ideal for carrying updates over from our CMS to Elasticsearch. Whenever an update is made by a CMS user, our content API pushes the updated record’s ID into an AWS Kinesis stream, which kicks off a Lambda function running our second Python script. This script uses the same shared library as the CLI tool to fetch any updated records and refresh them in the index. This process has proven to be quick and reliable, with search results often updated by the next refresh interval (in our case, 1 second).
Clean Queries In Our Code
Elasticsearch queries are intuitive and very nice to work with, but they can get quite verbose, especially when working with compound or nested queries. This, in turn, can make application code messy and difficult to manage when building complex queries. When adding new features driven by Elasticsearch, these queries can get exponentially larger.
So how can we make these easier to manage and build in code? At first, we tried using a functional approach to be able to compose queries. This ends up looking nice in the application code, but it does have some drawbacks. Elasticsearch queries are essentially JSON objects; representing them as functions in code just seems a little unintuitive and can end up adding more complexity than necessary. It also becomes more difficult to read ‘at a glance’ exactly what queries are being executed in Elasticsearch.
This brings us to the next approach that could be taken, which is writing out the JSON queries, either in the code, or in imported files. This solves the readability problem; it’s about as explicit as you can get. However, with this approach it becomes difficult to run conditional queries (ie. an optional filter, etc.).
We’ve taken the approach of using EJS templating within our search application to construct flexible, dynamic queries that are still extremely explicit and easy to read. This approach also allows us to build search queries using independently-written building blocks, which can each be isolated and tested individually as part of our continuous integration process. It is, in my opinion, the best of both worlds.
Inadvertently, using a templating mechanism to build our queries in the application logic also gives us a solution for testing the quality of queries. Templating queries makes it easy to run A/B tests by allowing the front end to place a query parameter on requests indicating which variant should be used.
…Back To Discovery
Now that we had a solid search (and search indexing) infrastructure, we decided it was time to take the first step toward content discovery. As mentioned above, we wanted to be able to take what we know a user likes, and use that to score other documents in order to recommend them to the user. The first iteration of this was simple — if a user read the article to the end, we’d assume they liked the article, so we’d use Elasticsearch to curate a list of other ‘related’ articles they’d like, and present them as the next articles in an infinite scroll module.
We constructed new search queries that, instead of looking for user-defined terms in documents, use a series of ‘more_like_this’ queries to find similar content to what the user has read in their current session, as well as boosting scores of documents based on content age, display type, etc. George Jeng, our growth product manager, led our move toward incorporating more NLP-based entity extraction from our articles, which provided valuable signal to our relatedness queries. When A/B tested against our old method of retrieving next articles for infinite scroll, this new feature performed significantly better with users.
Where to go from here
Without even considering a user’s history, there are numerous factors that we could incorporate into a query to make it more accurate for a given user. Some things we’ve considered are:
- Tagging content with geographic coordinates representing where it’s based, and using a decay function to boost scores of records that are ‘closer’ to a user
- Boosting content based on it’s length (or duration, for videos) depending on what type of device the user is on or what time of the day it is
- Applying boost for trending topics or articles related to what the user is reading
We’ve managed to greatly improve user engagement by reusing our Elasticsearch indices in a relatively simple way. So what’s next? By factoring in users’ favorite topics, contributors, content types, etc., we can begin to use more personally tailored Elasticsearch queries to be sure we’re finding the right content for each person on our sites.






