

DataOps and the Data Platform


They say that data, if tortured enough, will confess to anything. Maybe this is the explanation behind how and why data became a buzzword by the end of the 90s when hard drive production costs decreased dramatically due to the exposure and adoption of the internet. It became much easier to own, analyze, and use its results to make pivotal decisions based on almost prophet-like powers.

Naturally, large corporations and organizations began stocking up on virtual space. But if space grew, shouldn’t the amount of time it took to manipulate or read the contained data increase exponentially?
To answer that, rewind back to 1965 when Intel co-founder Gordon Moore discovered that the number of transistors on a chip doubles every year while the costs are halved. This gave us the ability to store and process more data in less time!
More space and more powerful processors led to more data being stored, accessed and distributed. Here is a flowchart to illustrate:
cheap disks –> big data –> cloud computing –> mass analytic tools –> data scientists –> data science teams –> new analytic insights.
This process gently shifted us into the Information Age where the economy is based on information technology.
Companies that owned or stored data, or designed applications to connect and visualize it, or developed innovative ways to ETL data faster, became highly valuable. These companies became indispensable and highly-dependant on the tech industry and by the whole economy. Not surprisingly, the necessity for more specialized roles within the data platform grew in these organizations. This is where DataOps fills the void.
DataOps can best be described by Andy Palmer, who coined the Pascal-cased word, “The framework of tools and culture that allow data engineering organizations to deliver rapid, comprehensive and curated data to their users … [it] is the intersection of data engineering, data integration, data quality and data security.”
Fundamentally, DataOps is an umbrella term that attempts to unify all the roles and responsibilities in the data engineering domain by applying collaborative techniques to a team. Its mission is to deliver data by aligning the burden of testing together with various integration and deployment tasks.
But is this comparatively new unit necessary? Let’s look at the flow of data and role responsibilities within a typical organization to see how each role interacts with the data and each other. Maybe it can help shed some light on why this role is becoming mandatory in tech.
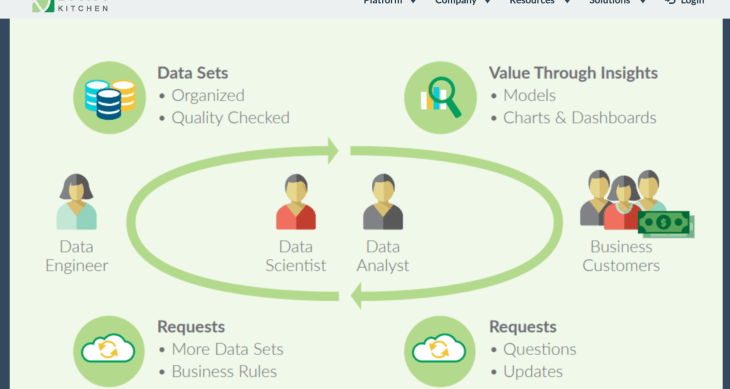
Data science projects usually end up being very large and expensive IT implementations with limited to no measurable ROI. They are cumbersome, time-consuming and sisyphic. As Christopher Bergh describes it: “The story of the DevOps movement is that old infrastructure, lack of testing, and complicated monolithic backends slowed down everyone in an old, big enterprise.”
The tree of dependencies and the fact that there’s no overlap between roles slows down the whole process of retrieving, manipulating and supplying the final product to the end-user. The aim of DataOps is to make this process more efficient. As Christopher Bergh states in this episode, “DataOps is the recognition that a set of problems have crept into organizations over time and slowed down productivity… [it] encourages data driven organizations to begin with a similar practice of testing their data pipelines to build trust and evolve best practices.”
DataOps allows consumers to help hand-select data. The consumers become more involved the more they interact with the software. They feel more much comfortable with the systems and become engaged in the operations, thus displaying confidence in the results. It enables end-users to make corrections to the data as they consume it. These iterations result in innovation, the key metric for the success of an organization. This is why the field is so important in an organization. But it only recently rose in importance and its definition is still fluid.
Since the field is still in its beginning stages, its responsibilities are, at times, unclear and ambiguous. Every organization has its own set of duties and expectations from its DataOps unit. But there are some still some well-defined tasks that have already been transferred to this evolving corner of the tech industry.
Andy Palmer states that, “[DataOps] projects start with an analytic outcome in mind, and then focus on unlocking value from across data sources and lines of business, enabling users to quickly build analytics that they need”.

Its tools allow non-developers to build pipelines and share them between team members to allow iterative development. Pat Patterson describes the DataOps’ role in an organization as “supporting an iterative lifecycle for dataflows, including building, executing, and operating steps supported by data protection.”

The process of handling data, maintaining its pipelines, and analyzing it is of high importance. And so are the expectations from whoever in the organization is involved in DataOps. Speaking on the subject on one of our podcast episodes, founder and Head Chef of DataKitchen, Christopher Burgh, describes that the main expectations and challenges facing DataOps today are:
- How do you deliver data faster to your end-users?
- How do you maintain high data quality with as few errors as possible and still carry out the correct deployment strategy?
- How do you still let your team innovate?
All this work is done primarily by ‘splashing’ code into an IDE or scribbling architectural diagrams on the chalkboard, connecting deformed circles and squares; the actual work is much like any other branch of development.
In other branches though, say software development, once you compile and deploy your application, it is not expected (in most cases) to run persistent tests on it. It becomes its own static and uniform entity. It’s almost foolproof.
With data, a company needs to constantly execute tests to verify that the data is ‘clean’ because to handle customer data efficiently. The last thing you want to do is serve them with the wrong numbers. You need to set up and develop tools and alerts to monitor the memory on the box to make sure that it isn’t blowing up because of an unexpected M2M caused by your end-user joining two tables’ foreign keys and pushing. You need to work with the front end to make sure that the query translator component doesn’t cause the UI not to render and load fast enough in order to prevent the customer from waiting for 30 seconds to see his dashboard.
Not only is working with data more tedious and the crises caused by its malfunction apocalyptic (e.g., because Big Data operations are resource-heavy so servers are more prone to crash when an unexpected query gets executed by end-users), but also the build and deployment tools for DevOps, DataOps’ distant cousin, are far more mature, widespread and flexible (Gradle comes to mind). The technology isn’t quite there yet and neither are technological methodologies. For example, the Agile Method needs to be confronted as it is now the norm. Agile sprints are incremental and iterative by definition, which works great with the iterative nature of DataOps, but we all know that database and server-side development and deployment tasks sometimes can’t be measured in months, let alone two weeks!

In addition to the the tools and methodologies, yet another challenge is that most cultures in conservative organizations impede on harnessing the power of Big Data. Although we do see the trend of spilling money into Big Data projects and companies generally embracing them, the highly-gratifying outcomes of these projects haven’t reached their potential yet. Although we mentioned that the data engineering technology stack is a little behind compared to its counterparts, we shouldn’t blame the stack if projects aren’t yielding the desired returns. We should first challenge the mentality and culture of the said organization.
The future and adoption of DataOps in the tech industry is contingent upon the mindset of the people making up the organization. Spending less time thinking about technology and more time addressing people and cultural issues may help organizations deliver data that users will use, and result in meaningful returns from their Big Data investments. To quote Jack Welch, former CEO of GE, “An organization’s ability to learn, and translate that learning into action rapidly, is the ultimate competitive advantage.” It’s the people that create value and not vice versa.






