

Cloud Deep Dive: Part 2 — Serverless Stock Service


Pakhnyushchy/Shutterstock
This post was originally written by Pieter Raubenheimer on Medium. Reposted with permission.
In Part 1, we started building out the Cloud Pizza Place — a virtual restaurant in the cloud, to see some of the patterns and nuances of serverless computing.
Using cloud managed services should increase our ability to build our software as smaller, more isolated parts, allowing for greater team autonomy and creating more opportunities for innovation at scale.
In Part 1 we covered Baking and today we’ll focus on Ingredient Supply:

If you haven’t yet seen the Serverless Pizza Oven baking in Part 1, check it out. We’ll use the same environment: AWS, IAM, CloudFormation with SAM.
The working source code is available at github.com/yldio/cloud-pizza-place.
Functionality
The narrative is something like this:
- Ingredients arrive in batches.
- We need to keep them until they either:
a. reach their best-before date — they expire, or
b. get used when assembling pizzas. - Our menu system needs to know what ingredients we have, in order to allow for the Chef to design and publish possible menu options.
Receiving stock
Our suppliers deliver ingredients in a simple CSV file format. We’ll let them drop these CSVs into an Amazon S3 bucket. Amazon S3 buckets store objects (a.k.a. ‘files’) and provide Internet-facing endpoints that can be configured for read/write access with multiple means of access control.
The files we’re expecting would look something like this:
ingredient,quantity,best_before pepperoni,2000,2019-03-15 mushroom,1000,2018-11-30 pineapple,500,2018-03-15 ham,3000,2018-12-31
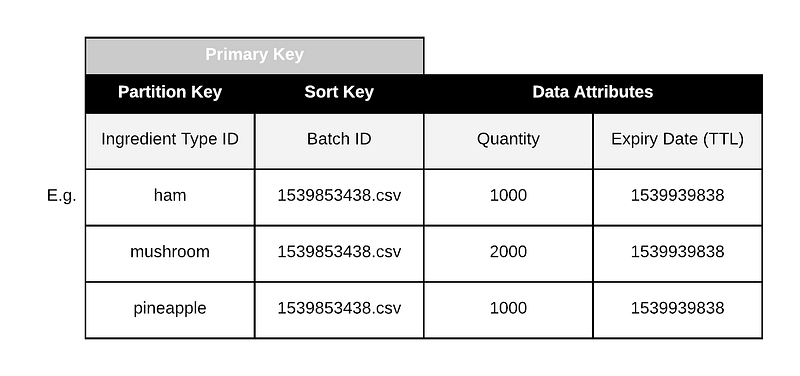
We’ll want to write this data to a database table dedicated to our service. We can use DynamoDB again and structure the table with the ingredient name as part of our primary key. With DynamoDB you need to think about how you will want to retrieve data when constructing the key. To retrieve or modify rows later you will need to be able to reconstruct it.
The primary key is made up of a partition key and sort key. Rows that share a partition key are stored close together, making retrieval faster and cheaper. We can use the unique file name as an identifier for batches, and use it as the sort key, ensuring that the primary key is unique for every incoming row. (Note: this assumes only one row per ingredient per batch.)
We can add a NotificationConfiguration to our S3 bucket (in our CloudFormation template) to trigger a Lambda function to do the DynamoDB update every time a new file arrives:
StockBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Ref StockBucketName
NotificationConfiguration:
LambdaConfigurations:
-
Function: !GetAtt StockReceivedFunction.Arn
Event: s3:ObjectCreated:*
We’ll also need to explicitly allow S3 to invoke this function for events from this bucket:
StockReceivedInvokePermission:
Type: AWS::Lambda::Permission
Properties:
Action: lambda:InvokeFunction
FunctionName: !GetAtt StockReceivedFunction.Arn
Principal: s3.amazonaws.com
SourceAccount: !Ref AWS::AccountId
SourceArn: !Sub arn:aws:s3:::${StockBucketName}
The notification messages only contain some metadata for the new file, not the full contents, so the Lambda function needs to read it from S3. We’ll set up the relevant permissions in the Lambda’s IAM execution role.
We now have something like this:

Keeping count
As it stands, it would be rather expensive and tricky (if not impossible), to reliably retrieve the total quantity of stock on hand from our DynamoDB table. We should create a single row for each ingredient that keeps the aggregated quantity, the sum of all batches for that ingredient. Updating this value will be for us to implement within our system.
In distributed systems, we have many pieces of infrastructure that cannot guarantee that the same message won’t be delivered twice. Lambda retry behaviours are just the start. We should therefore always try to make our Lambda functions idempotent, i.e. repeatable without changing the result from its initial application.
We know from Part 1 that we can use Condition Expressions to achieve atomicity per database table row. To avoid recording the same batch twice on our aggregate row, we can keep a set of Batch IDs on this row. E.g.

Our command would include:
UpdateExpression: `
ADD quantity :incr,
batches :batch
`,
ConditionExpression: 'NOT contains (batches, :batch)',
ExpressionAttributeValues: {
':incr': {
N: String(quantity)
},
':batch': {
SS: [batchId]
}
},
If we gracefully accept conditional expression failures, we can rest assured that the integrity of our aggregate row is protected.
(But what about the size of that column? Won’t it become massive? Well, that should be taken care of when we expire our batches of ingredients…)
Expiring ingredients
DynamoDB offers a free of charge feature to delete records based upon the value of a specified timestamp column (TTL). It does not guarantee high accuracy and there could be some lag, typically a few minutes, but we’re not that concerned about exact expiry time, so we’ll use this feature.
If we let individual batch rows be deleted based on the expiry date, we need to consider that our aggregate row will become out of sync. So we can embrace Eventual Consistency. If expiry is not that time-sensitive, we can tolerate some temporary inconsistency here.
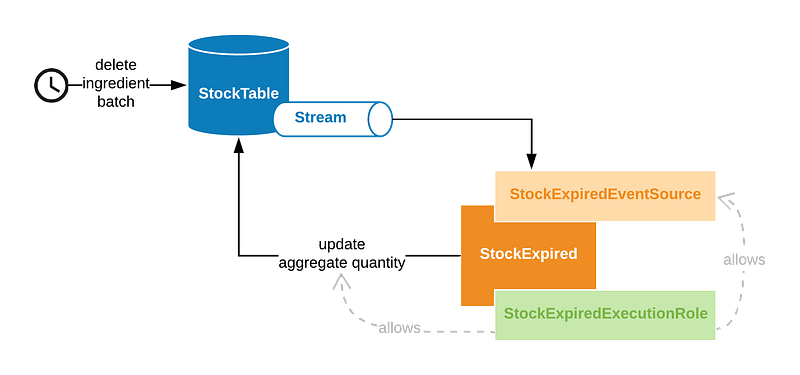
To bring it back in sync we’ll update our aggregate row from a Lambda that we can trigger every time a row is deleted from our DynamoDB table. To do this, we’ll attach an Event Source Mapping to a stream of activity on the table:
StockExpiredEventSource:
Type: AWS::Lambda::EventSourceMapping
Properties:
EventSourceArn: !GetAtt StockTable.StreamArn
FunctionName: !Ref StockExpiredFunction
StartingPosition: LATEST
We can again use an operation with a condition expression to safely delete the batch and remove the relevant quantity from the aggregate row:
UpdateExpression: `
ADD quantity :incr
DELETE batches :batch
`,
ConditionExpression: 'contains (batches, :batch_str)',
ExpressionAttributeValues: {
':incr': {
N: String(-1 * quantity)
},
':batch': {
SS: [batchId]
},
':batch_str': {
S: batchId
}
},
So it will work something like this:
Using ingredients in stock and telling the world
We want other parts of our system to be able to use the ingredients we have in stock. They would be requesting ingredients in transactions that should only succeed if all the ingredients in the transaction are available in sufficient quantities.
We can expose an HTTP API that calls a Lambda function using AWS API Gateway. API Gateway has many features to help publish, manage, monitor and secure APIs for services running in AWS.
We’ll expose an HTTP POST API that takes JSON requests like this:
{
"transactionId": "abc123",
"items": [
{ "typeId": "ham", "quantity": 10 },
{ "typeId": "mushroom", "quantity": 10 }
]
}
Such a transaction would require multiple, separate database operations. Doing these operations on our aggregate rows lets us achieve atomicity per ingredient and simplifies implementation of rollback in the case of any one of the operations failing, such as when there aren’t any more of a particular ingredient.
We must reflect the actual remaining ingredient quantities on batch rows so that those would remove only the remaining stock upon expiry. This reconcilliation process would involve an algorithm that would remove stock from oldest batches first. We can implement this within a Lamdbda function attached to a stream of table activity as before.
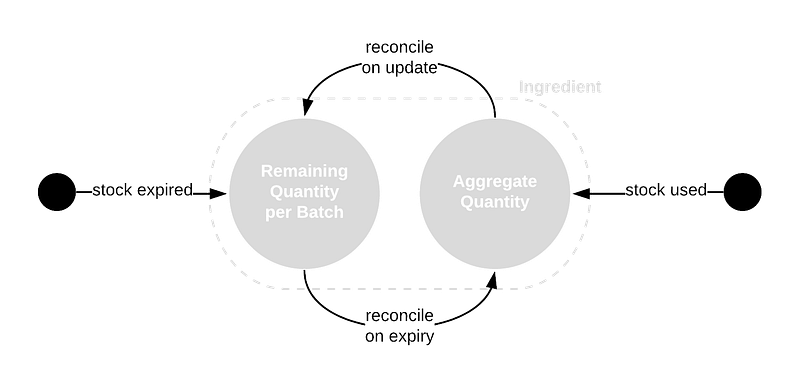
To broadcast updated stock counts, we can set up this same function to publish updates to an AWS Kinesis Data Stream. Other services would later be able to get records from this stream to analyse or reflect wherever they need to.

All together now
We can create a script to simulate it all working together. The script would listen to our Kinesis stream to plot an ingredient’s stock level in the terminal. We’ll let it use a limited, randomised, amount of stock every few seconds and we’ll drop some new stock into S3 every minute.

We can see how it takes a few minutes to start expiring stock.
And that’s it. You can take a look at the source code at github.com/yldio/cloud-pizza-place.








