Cloud Dataflow with Eric Anderson

Podcast: Play in new window | Download
Subscribe: RSS
[SCM]actwin,0,0,0,0;Zoom Player zplayer 6/27/2014 , 5:11:38 PM

Batch and stream processing systems have been evolving for the past decade. From MapReduce to Apache Storm to Dataflow, the best practices for large volume data processing have become more sophisticated as the industry and open source communities have iterated on them.
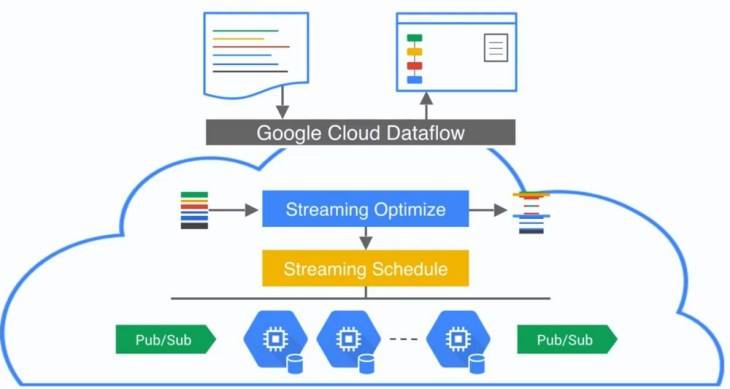
Dataflow and Apache Beam are projects that present a unified batch and stream processing system. A previous episode with Frances Perry discussed how they work in detail. In today’s episode, Eric Anderson discusses Cloud Dataflow, a service from Google that lets users manage their data processing pipelines without having to spin up individual servers to run them on.
Cloud Dataflow–like the “serverless” movement we have done several shows on–represents a growing shift towards cloud providers offering services that abstract away the operational challenges of managing compute nodes. If you have suggestions for topics in this area, please do send me an email.